Making data – trustworthy, accurate data – available to the people that need it can be a frustrating process. And it often falls to business systems analysts to be the bridge between business users (maybe in the Finance or HR teams for example) who need the data, and the IT or technical teams that need to supply the data.
In this post we'll show you how you can overcome some of the typical challenges you can face when trying to make reliable data available, and instead take control over data (even if you don't own it) and get it to users in a clean, usable format.
If you’re a business systems analyst (BSA), you probably want to make the process of getting hold of data easier, but the realities of life can make this difficult. You likely have to deal with:
- Manual work that could be eliminated: Wasting time on things that can (and should) be automated leads to errors, frustration, and delays in getting work done.
- External dependencies: Having to wait for someone else – whether it’s an IT team or a single overloaded person – means waiting, downtime, and projects taking too long.
- Technical challenges: Supporting your team often requires working with other teams or departments that can have different technologies that you need to try to work with or integrate.
- Emotion: There’s often a lot of emotion around innovation projects. The memory of previously failed attempts to improve or fix a process can leave some resentment towards adopting certain approaches.
- The desire for perfection: There can also be a desire to build the ‘perfect’ thing – a noble goal, but people who’ve been part of these projects before often know that the perfect thing rarely happens, and it’s better to aim for something rather than wait for that utopia.
The Business System Analyst checkmate
One of the unfortunate things about being in a liaison role between multiple teams is that you’re locked between forces that make your life a little difficult.
You need to provide access to, and governance over, data that you don’t own.
And you know the importance of getting that data quickly. Which means you don’t have time to wait for multiple other teams across the organization to implement some ‘perfect’ solution (which you know will likely never actually get across the finish line).
The solution? You need to work around these obstacles and create an ‘invisible’ solution, which also usually means something relatively low on budget and easy (and quick) to implement.
Data democratization
The goal of data democratization is to make data from across the business accessible, so people can be self-sufficient, without needing an excessive amount of manual work and without the downtimes that can come from dependencies on other teams.
Getting access to the data you own, or that’s in your own ‘silo’ is usually easy. But democratization means people getting access to data outside their silo. And that’s where things get tricky.

So what are your options?
Build or augment an organization wide architecture
The problem with this option is that it’s too big of a project. It needs to be perfect to work as intended across an entire organization, and the realities of life mean it often isn’t perfect. There are a lot of dependencies on others, competing priorities and changing requirements.
The worst thing that happens with these kind of projects is that a big project gets started and abandoned halfway through, and years later another project gets started. So rather than one all-encompassing architecture you end up with lots of little pieces that serve different parts of the organization but are disconnected from each other.
So while it might be a slight improvement you’ve essentially ended up with just bigger silos.
Provide access to raw data
Another option is that you give people access to the raw data, whether it’s the applications themselves or a data lake or lake house where you consolidate all the data and leave it to users to make sense of and be efficient with it.
The challenges with this option are firstly, and obviously, governance and security issues. But there’s also challenges around skillsets. New applications or storage such as data warehouses require skillets that business users might not have, and it can take a lot of time and effort to get usable data from that.
Embrace the situation as is and provide a federation layer
The final option is that you decide you’re not going to try and change too much of the architecture that’s already there, but you’re going to provide a layer on top to provide access to what’s there without too much hassle.
The potential pitfall with this option is that it can also easily balloon to a big complex project. But with the proper tooling and approach you can simplify it so this becomes the easiest one to get done and start seeing results from.
How CloverDX can help data collaboration
CloverDX is a data integration platform that can help technical teams (whether business systems analysts or IT teams) work together with users on the business side of the organization.
With CloverDX, it’s easier for business users to work with data on their own – but not in isolation. The data they’re working with is provided by the technical teams, which means it’s reliable, accurate, and pre-cleaned.
How can you make data available to business users – even when you don’t own it?
The checkmate that we talked about earlier comes down to making data that you don’t have control over available to end users.
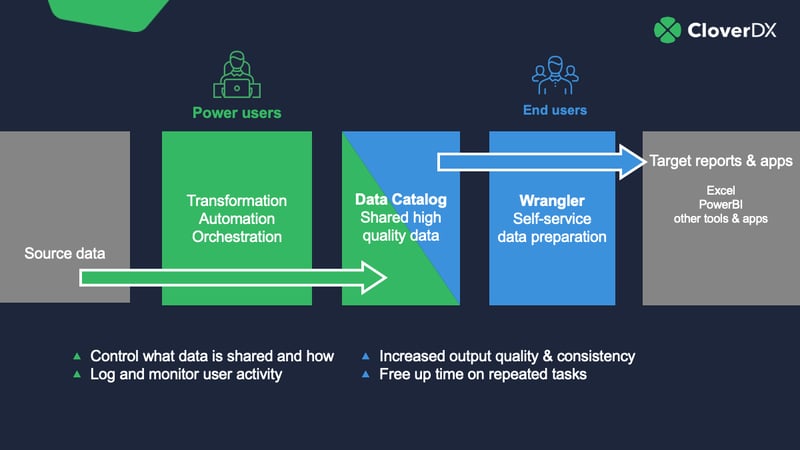
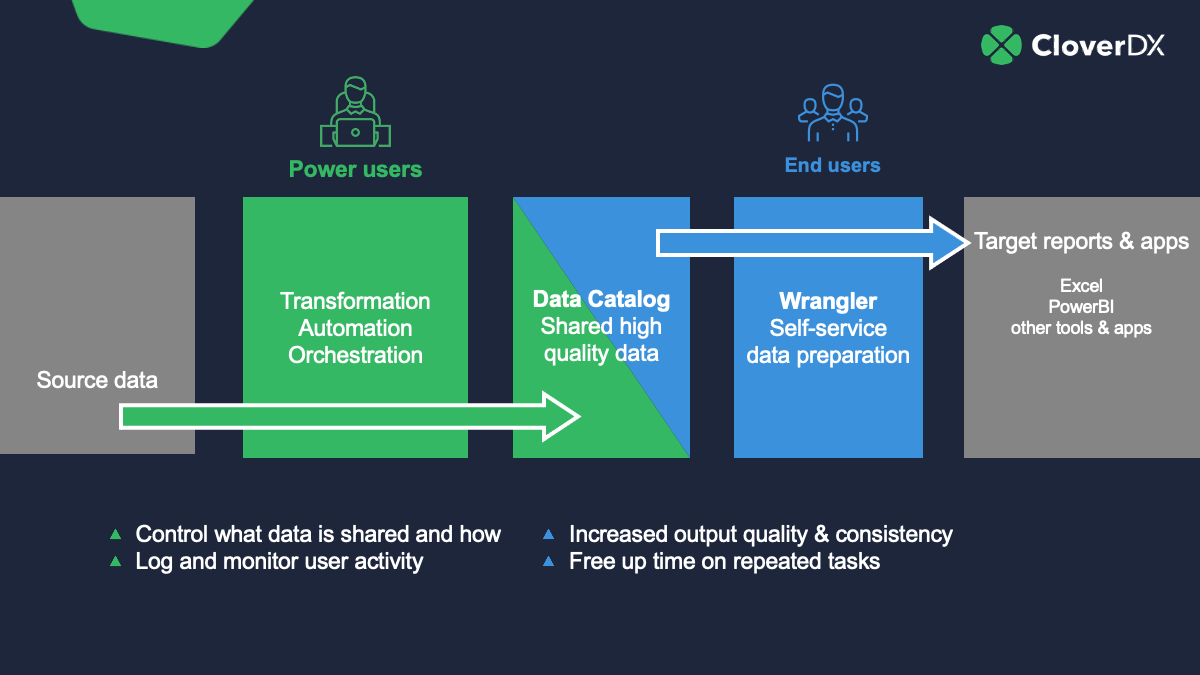
You might not have control over the raw data or the source systems (the area in the grey box on the left in the diagram), but with CloverDX you can have control over the green section – transformation capabilities that can make data into something business users can work with.
You can build transformations that turn the raw data into high-quality, validated data that you can put in a Data Catalog, where business users can access, work with and export it via an easy-to-use interface.
The Data Catalog
The Data Catalog in CloverDX is the central bridge between you and the end users. You can publish data to it, and non-technical users can consume it.

You can make that data ‘trusted’ – you take data from the source and combine it, transform it or otherwise manage it to get it into a usable format. And as the connection is to the source system, the data users get is live whenever it’s requested.
You also have complete access control over what each user sees.
From the business user point of view, it’s a central place where they can find all the data from across the organization that they have permission to see. And they avoid data prep hell – it eliminates the pain of getting to the data in the first place, and having to spend hours (or more) making it into something usable.
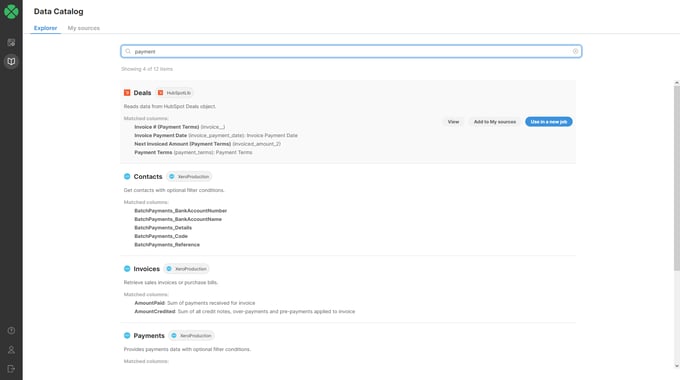
Search results in the CloverDX Data Catalog
Publishing data sources and targets with CloverDX
CloverDX is one platform with different interfaces for different users, meaning you or other technical users get access to all the power and configurability you need, and the complexity is hidden from the non-technical end users, who just get the data they need.
The CloverDX Designer
The Designer is where you build connectors and transformations. It allows you to connect with any source, and you can build even complex transformations for your data.
CloverDX Server
Server is where all the automation and deployment happens – from here you can deploy the connectors you’ve built to the Data Catalog, plus control which groups of users can see the data in their Data Catalog view.
Wrangler
CloverDX Wrangler is the business user interface where non-technical users can find and work with data that you’ve published to the Catalog.
With Wrangler, a self-service data transformation platform, business users don’t need to code, or understand the rest of the CloverDX platform, they can just work with ready-prepared data in a familiar interface.
Users can record each transformation step they do, so a whole series of steps can be repeated at the click of a button. At each point users can see what the data looks like, and see a validation summary that highlights any errors, such as an incorrect format.
Working with data made easier for business users
How does CloverDX can help business users save time and improve data quality?
- Increase productivity – users no longer need to waste time hunting for data, they can rerun jobs at the click of a button, and perform repetitive steps quickly and easily.
- Eliminate ad-hoc data requests – no more having to ask the technical team to export data from a particular system whenever they need to do something. With Wrangler they can access and use the data directly, with no waiting around.
- Higher quality data – The data users are accessing is validated, clean and easy to access – higher quality and easier to use than raw data.
- More trustworthy outcomes – Being able to see validation results and what’s happening with your data at every step of the transformation means your outputs are more trustworthy than relying on an Excel macro.
Beyond just accessing data
As well as creating data sources in CloverDX, you can also create data targets – so you can write data to anywhere. And like with data sources, you can add additional behavior to the target, so you’re writing not just raw data, but you can for example validate it, add to or enrich it.
Data mapping
A data target can define the format the target requires, so users can easily map data to that format with Wrangler’s visual, drag and drop interface.
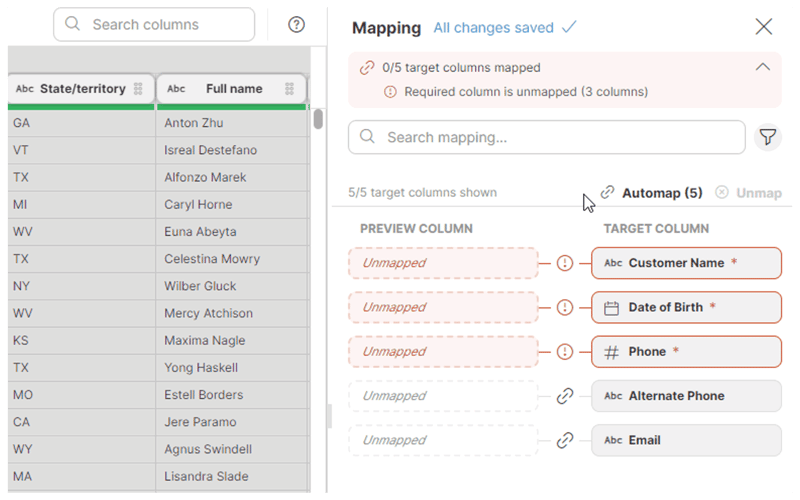
Data mapping in CloverDX Wrangler
It’ll also give you immediate feedback if something is wrong (like you’re trying to map a number format to a field that requires text).
And once the end user (often the domain expert) has provided that mapping, they can export it from Wrangler, and your organization’s technical teams can integrate that mapping into a bigger process, within CloverDX Designer.
What’s happening in this example is that one part of a larger data workflow is using the mapping that the business user has created in Wrangler, and it's this mapping that's driving the overall processing of the files. The business user can contribute their expertise, though a simple, familiar interface, and not have to worry about the more technical parts of the process.
The whole end-to-end workflow can then be automated to run on a schedule or on a trigger.
And because everything runs on the same platform, you get complete visibility of all the jobs that have run, making it easy to investigate and troubleshoot any issues.
A complete platform for data collaboration
With CloverDX you get a data platform that enables both business users and technical users to work together, on the parts of the process they’re best at.
The domain experts get to work in an interface that’s simple to use, and what they produce can be integrated by technical users into larger pipelines that take care of the whole end to end process.

Share







