Upcoming and recent webinars


What's new in CloverDX 7.5

What's new in CloverDX 7.4

CloverDX Masterclass: The Art of Going Parallel
Running a Healthy CloverDX Server II: Troubleshooting

Running a Healthy CloverDX Server I: Configuration Best Practices

What's new in CloverDX 7.3

How Faster Data Onboarding Fuels Customer Acquisition and Growth

Cracking the Build vs Buy Dilemma for Data Integration Software

A Guide to Migrating Data Workloads to the Cloud
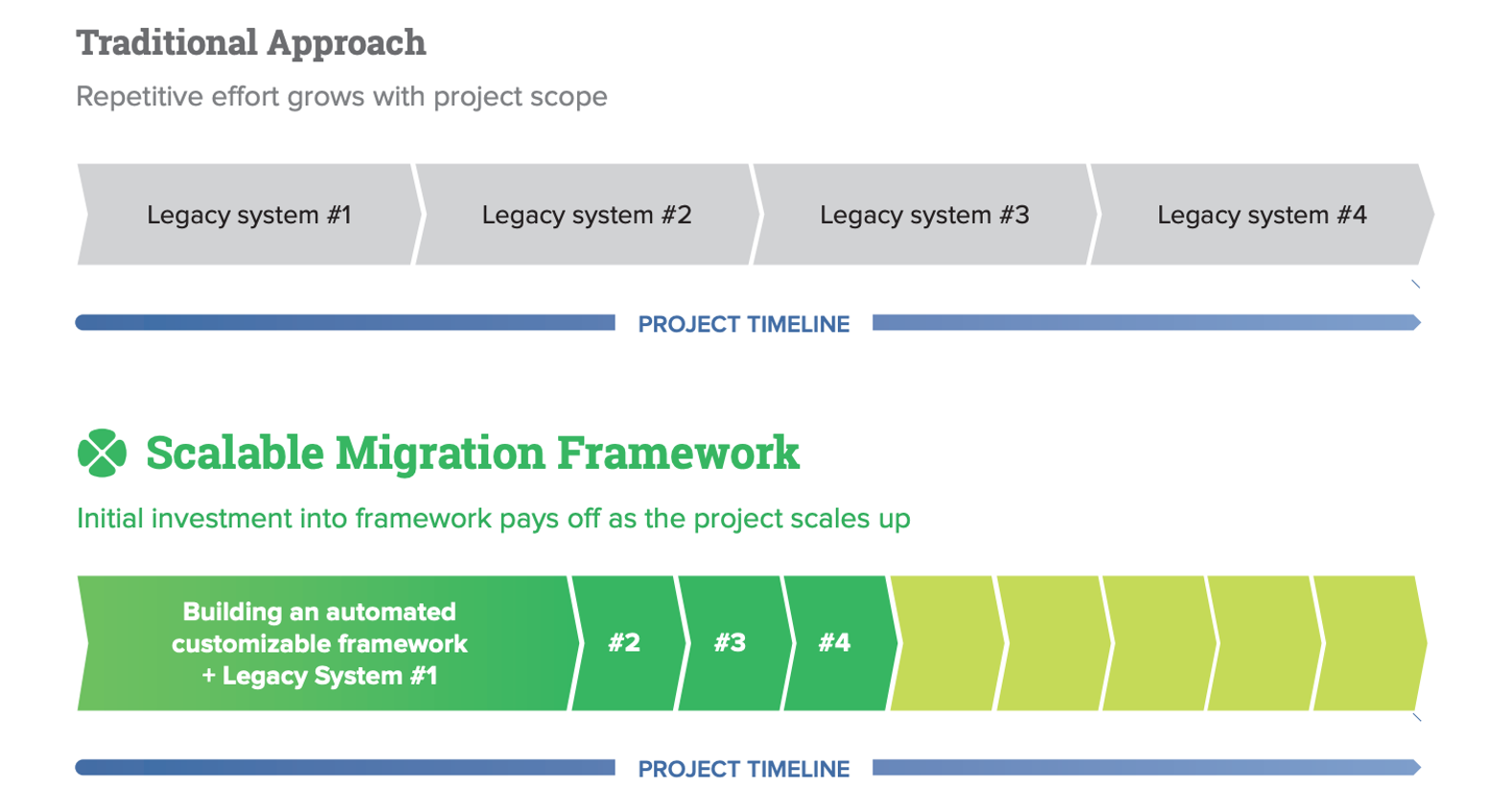
Building Large Scale Data Migration Frameworks

How to Bridge Data Models and IT Operations for Simpler Compliance

Buyers Guide to Data Integration Software
Architecting Systems For Effective Control Of Bad Data
Your Guide to Enterprise Data Architecture
Designing Data Applications The Right Way

Data Migration for Humans. What makes a data migration successful?
