This article explains where AI outperforms rules, where it introduces risk, and how to apply it without weakening governance.
In 2025 Customer PII was the most stolen or compromised data type, appearing in 53% of breaches. The global average breach cost reached USD 4.44 million, which raises the cost of misclassifying or mishandling sensitive data.
Many pipelines still rely on fixed rules to label data, mask sensitive fields, and flag abnormal records. Those rules work when schemas stay stable, field names stay consistent, and sensitive values appear where the pipeline expects them.
Modern pipelines rarely operate that way. Free text, mixed formats, and record structures that change without notice are now the norm. When the data drifts, the rules break, and sensitive data gets missed, masked incorrectly, or passes through unchecked.
ML models handle that variation without an exhaustive ruleset. But many AI services process data on third-party infrastructure, creating a new privacy and control risk.
Where rule-based systems hit a ceiling
Rule-based systems were built for a predictable data environment. As schemas change, sources multiply, and unstructured data becomes the norm, the maintenance burden of keeping rules accurate grows faster than the pipelines they govern.
Maintenance load grows faster than the pipeline does
Rule sets expand with every upstream change. Schemas shift, fields get renamed, and vendors restructure exports without notice. Each change triggers manual updates, and those updates rarely stay isolated. A fix for one source can quietly disrupt logic that was already working elsewhere.
Pattern matching cannot read context
A regex can detect a string that looks like a name. It cannot tell whether "Apple" refers to a person, a company, or a fruit in a customer feedback field. This gap leads to false positives, missed classifications, and masking mistakes that surface only after downstream damage is done.
Unstructured data sits outside rule-based coverage
Free-text fields, support transcripts, scanned documents, and chat logs carry PII in forms that pattern matching cannot reliably reach. Rule-based systems were not built for that category. Retrofitting them means maintaining a fragile workaround on top of a system already under maintenance pressure.
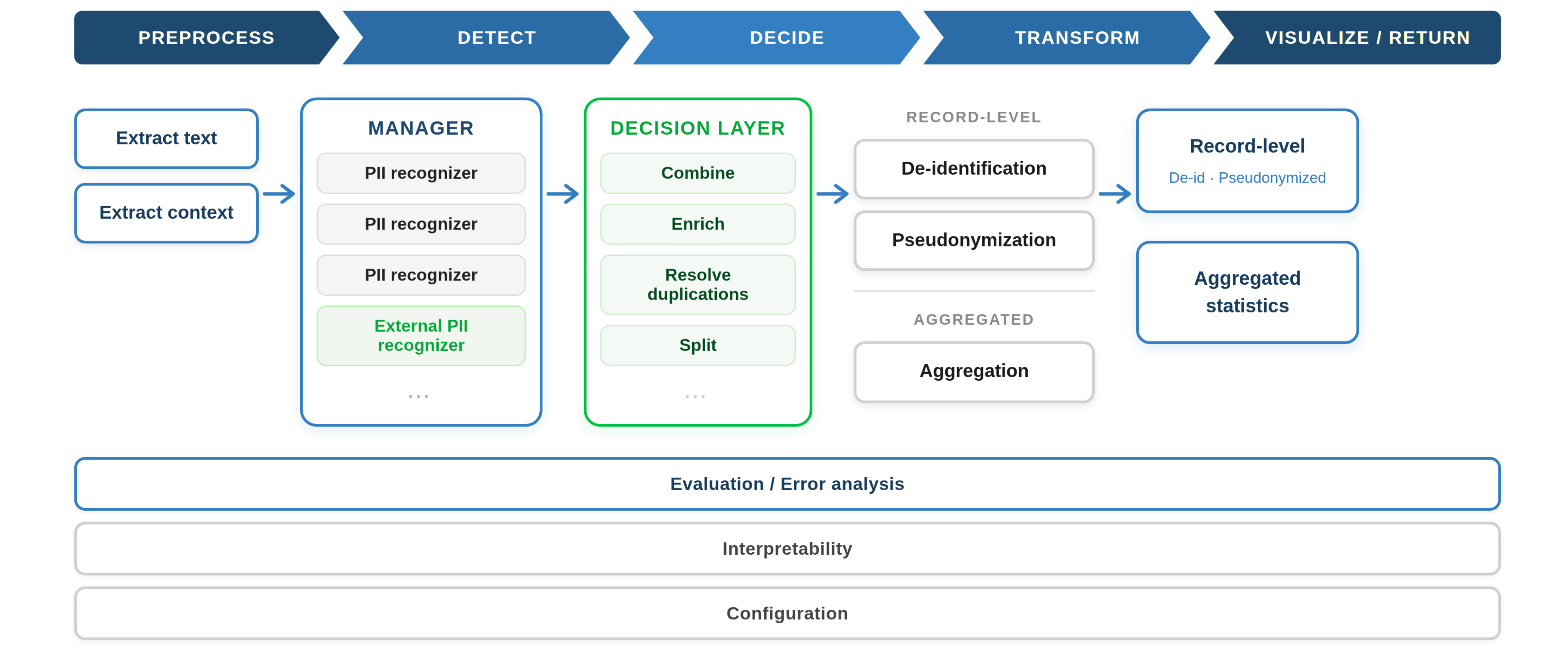
A contextual PII detection pipeline moves from text extraction through recognition and decision-making to de-identification, pseudonymisation, or aggregation at output | Source
How AI is reshaping three core data operations
AI changes the shape of three specific operations that rules have historically owned, without replacing rules wholesale.
The shift in data classification
ML classifiers score records against categories rather than checking whether a value matches a predefined pattern. That means they handle variation in phrasing, format, and word choice without requiring a separate rule for each variant. Zero-shot classification removes the retraining step entirely.
Teams define new categories in plain language. The model applies them immediately. That is useful when a new data source arrives and the pipeline needs to classify it before a full training cycle is practical. For high-volume tasks like sentiment tagging and ticket prioritisation, this reduces the false positive rate. That is where keyword matching becomes unreliable at scale.
The shift in data anonymization
Pattern matching can spot something that looks like a person's name. It cannot tell whether that text actually identifies someone in that specific case.
Token classification models like Microsoft Presidio and spaCy's named entity recognition read surrounding text to make that determination. That changes what gets masked and what gets preserved. For instance "Denver" stays visible as a city reference while "Frank from Denver" gets the name masked and the location preserved.
GDPR's Recital 26 and CCPA's definition of de-identified data both hold that data is not truly anonymised if an individual can still be identified from it by any reasonably available means. Pattern matching cannot provide that guarantee once PII appears inside free-text content.
The shift in anomaly detection
A pipeline can process 50,000 records on schedule, pass every validation check, and still be going wrong. A field that normally holds a near 50/50 gender split shifting to 70/30 will not trigger any alert. Silent shifts like these only get caught if someone anticipated the exact condition and hard-coded a threshold for it in advance.
McKinsey's State of AI report found that nearly half of organisations experienced measurable governance or ethical lapses tied to GenAI projects. Most of those lapses trace back to data quality problems the pipeline was not watching for.
AI models establish a baseline from the data itself and flag statistically meaningful departures from it without requiring a prewritten rule for every scenario. Gradual drift that produces clean pipeline logs while corrupting downstream outputs is precisely the category of problem a static threshold will never catch.
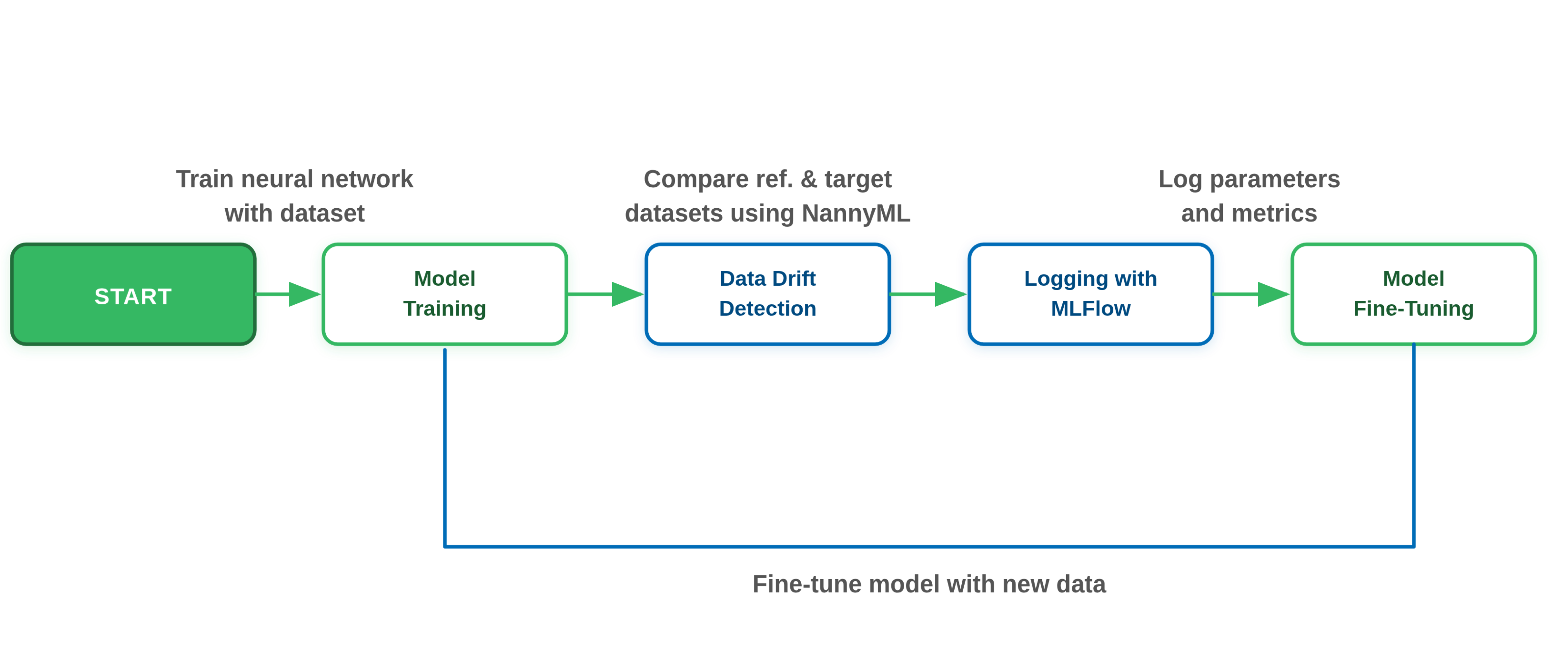
AI-driven drift detection catches the distribution shifts that static thresholds were never written to anticipate | Source
Where AI-driven approaches fall short
The gains covered above are real. So are the governance gaps that appear the moment AI moves from a proof of concept into a production pipeline.
Opacity and the audit problem
AI models are non-deterministic. The same record can be tagged differently across runs depending on model state, input ordering, or version changes. For compliance teams, that inconsistency is a practical problem.
Every classification, masking decision, or anomaly flag eventually requires a clear explanation for auditors, regulators, or compliance reviewers outside the data team. When an auditor asks why a particular record was flagged or masked, "the model decided" is not an answer that holds up under scrutiny.
Data exposure beyond the perimeter
Sending records to a cloud-hosted AI service for classification or anonymization means the data you are trying to protect leaves your environment. A model brought in to detect PII in a customer record has to read that record first, and if it runs on third-party infrastructure, the record travels with it.
Gartner predicts that by 2028, 50% of organisations will adopt zero-trust data governance because of the risks tied to unverified AI-processed data. Once a record crosses that perimeter, your governance obligations follow it, and most third-party AI services were not designed with that in mind.
Cost and latency at production volume
External LLM APIs charge per call and return responses over a network round trip. At proof-of-concept scale, neither factor is visible. At production volume, per-call charges across millions of records compound into significant costs, and round-trip latency accumulates into a throughput bottleneck.
A workload that costs a few hundred dollars in testing can cost orders of magnitude more in production. The latency that was acceptable for a sample becomes a throughput bottleneck across a full pipeline run.
Oversight gaps in everyday adoption
McKinsey reports that only 28% of organisations have CEO-level accountability for AI governance. Most teams adopting AI in their pipelines lack formal oversight structures.
Decisions about where AI runs, what data it touches, and how its outputs are validated get made ad hoc by the engineers closest to the implementation. Those decisions accumulate quietly until something goes wrong and the accountability trail is missing.
The answer is not avoiding AI but controlling where and how it runs. That means deciding which tasks run on locally hosted models and which use external services. Both need to be governed inside the same pipeline with full audit trails.
Explore real-world use cases for AI in CloverDX
Scroll through detailed examples of how AI enhances data transformation.

The case for a hybrid AI architecture
A hybrid architecture is the most practical way to introduce AI into a governed pipeline without weakening the controls already in place. It splits tasks between locally hosted ML models and external LLM services based on data sensitivity, volume, and complexity. The following steps outline how to put that split into practice:
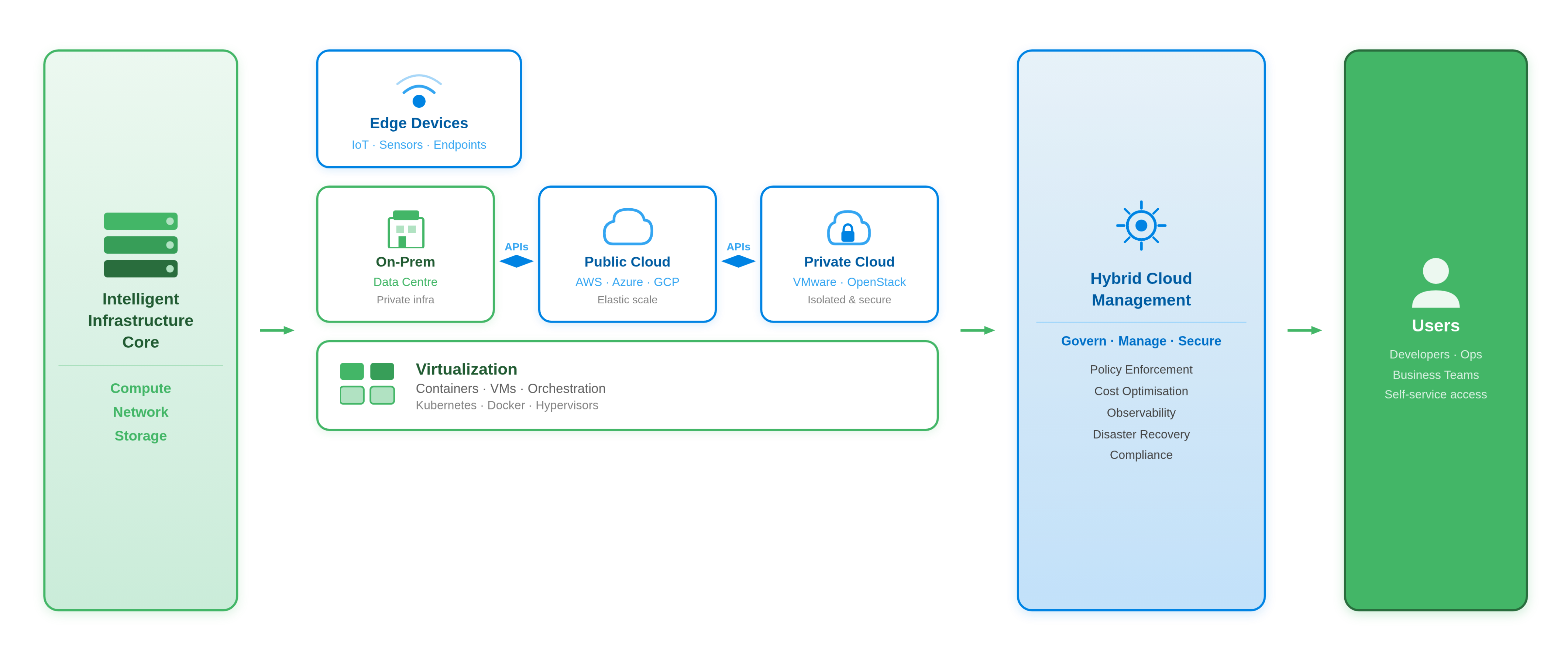
A hybrid architecture connects on-premises, public, and private cloud environments through a unified governance and management layer.
Keep privacy-sensitive tasks local
Small, locally hosted ML models are the right tool for classification, PII detection, and anonymization. Running them inside your infrastructure means sensitive data never crosses a perimeter.
Every inference is logged against a specific model version and outputs are reproducible. That is what makes an AI step auditable in the same way a deterministic pipeline stage is.
Fine-tuned token classification models now reach F1 scores above 90% on PII detection tasks across multi-domain datasets. That is the range where false positive rates become acceptable for production pipelines.
A 3 to 4 billion parameter model now runs reliably on a modest server, and in some cases on a mobile device, with performance that holds up well for focused tasks. PII extraction does not require a 100B+ hosted model, and running it locally removes both the cost and the latency of an external API call per record.
Reserve cloud LLMs for non-sensitive, low-volume tasks
External LLMs are better suited to tasks where the data has already been anonymised, such as summarisation, open-ended extraction, and natural language interpretation.
Limiting API calls to non-sensitive data keeps identifiable records inside the perimeter and keeps costs workable. Per-call pricing compounds quickly at production volume, and what looks affordable in testing can become a hard ceiling at scale.
Treat every AI step as a pipeline stage
AI components belong inside the pipeline as versioned, logged stages. Every inference should be traceable to a specific model version and input record. That traceability matters for three practical reasons:
-
Auditability means a classification decision can be defended and attributed, not just reported
-
Rollback means a model update that changes behaviour can be reversed without rebuilding the pipeline
-
Validation means outputs from a new model version can be compared directly against a prior run
The decision of when to reach for an LLM versus a smaller local model is a governance question. It should be made at the architecture level, not left to individual engineers.
How CloverDX implements this architecture
CloverDX 7.1 introduced purpose-built AI components designed for governed pipeline environments, not general-purpose AI tooling retrofitted onto a data platform.
Local AI Components for Privacy-Sensitive Tasks
Four components handle classification and anonymization by wrapping ML models that run directly on CloverDX Server. No data leaves your infrastructure:
-
AITextClassifier scores input text against a pre-trained set of classes
-
AIZeroShotClassifier lets teams define their own classes without retraining a model
-
AITokenClassifier breaks input text into tokens and scores them against a pre-trained set of classes
-
AIAnonymizer runs a token classification model to identify PII and masks the identified tokens in the output
Models can be downloaded from the CloverDX Marketplace or replaced with your own, including models sourced from HuggingFace or built in-house.
Connecting to external LLMs with programmatic output control
The AIClient component connects to OpenAI, Claude, Gemini, or Azure AI Foundry with built-in prompt chaining and response validation. Teams accept or reject AI outputs programmatically before they reach downstream systems. That keeps a deterministic check inside the loop regardless of which model produced the output.
AIClient also supports locally hosted models that conform to the OpenAI API specification, such as Ollama. That is useful for teams that want LLM-style interactions without sending data to a third-party service.
Both layers inside one governed pipeline
Local and external AI components run inside the same CloverDX pipeline. They share metadata, feed into a single audit log, and move through the same versioned deployment process. How that separation holds up under real privacy and security scrutiny is worth understanding before moving any AI component into production.
Start your 45-day CloverDX trial
Explore every feature, test real workflows, and see how fast you can deliver data pipelines.

Getting started without overhauling your pipeline
Start with PII detection and anonymization. It has the clearest compliance driver and a defined before-and-after. It also has the most direct connection to the risks covered earlier in this post. The common anonymization patterns most teams encounter are a useful reference for narrowing scope before committing to an approach.
Once that is in place, run AI classification in parallel with your existing rules. Compare outputs side by side before replacing anything. Rules and AI are not mutually exclusive, and a parallel run gives you the evidence you need to know which approach handles which records better.
Three things are worth tracking during that period:
-
False positive rate against your existing rules, to verify the AI layer is more precise, not just different
-
Processing time per record, to confirm the approach holds up at production volume
-
Governance audit-ability, meaning every classification decision is traceable back to a specific model version and input record
If any one of those falls short, the AI layer is not ready to replace the rule it was tested against.


Share







