Introduction
Data engineering has run on rigid, rule-based if-then logic for years. While the approach works well for structured data, it fails when the data is messy, inconsistent, or written in plain text.
Support tickets, legal contracts, and CRM entries are a few examples of such data. Writing rules to catch every variation in them is impossible and leads to constant pipeline failures. In fact, 38% of data workflows fail because of data quality issues that require manual intervention.
Large language models (LLMs) offer a solution. Instead of matching data to rigid rules, an LLM can read, interpret, and reason about it, much the way an analyst would.
Embedding LLMs into ETL workflows lets your pipeline handle nuance, context, and semantic meaning in transit without requiring a human in the loop for every edge case.
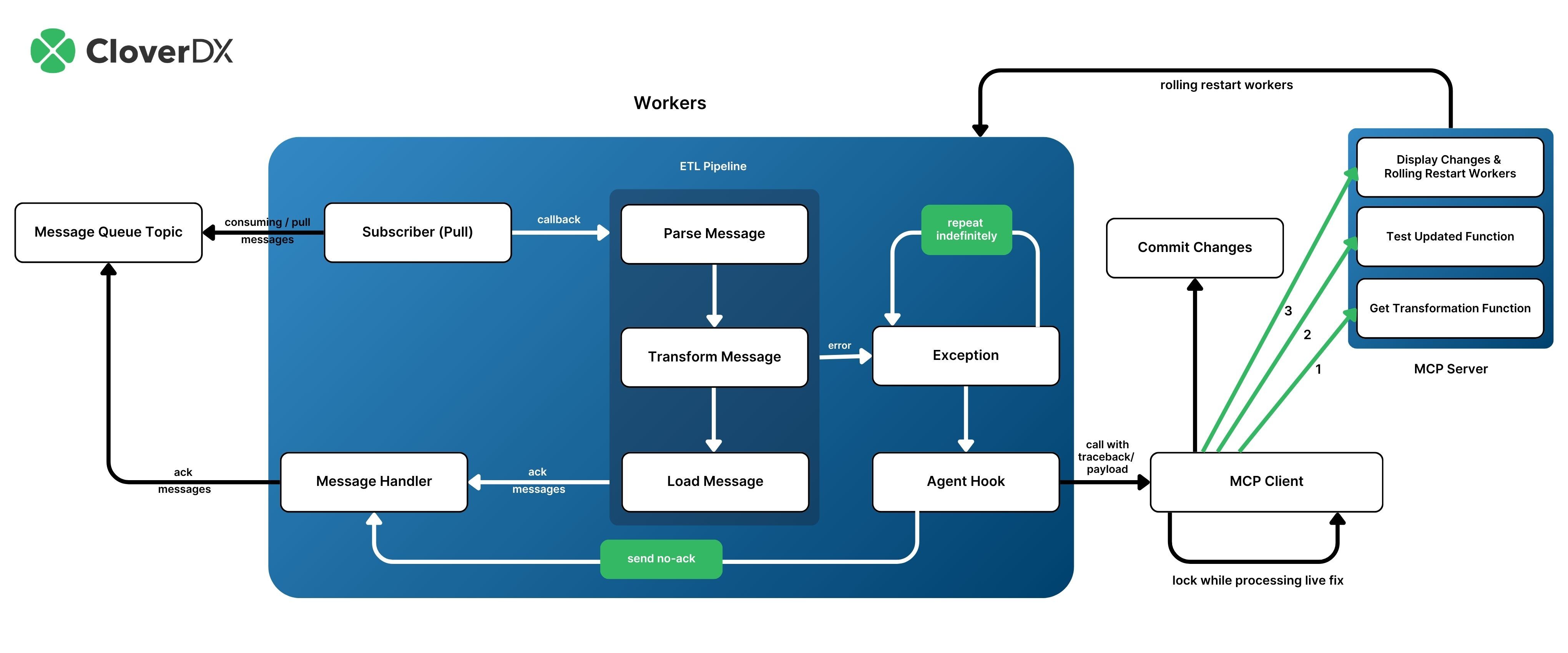
Diagram of Self-healing ETL pipelines with LLM | Source
In this article, we will explain where LLMs fit in modern ETL architecture and what use cases they serve best. We will also discuss how you can integrate them in a governed and cost-efficient way.
Understanding AI’s role in modern ETL pipelines
LLMs do not replace traditional ETL logic but expand upon it. Since traditional ETL steps, such as filtering records, joining tables, or calculating totals, are deterministic, they always produce the same output given the same input.
That predictability is exactly what you need for tasks such as payroll calculations or financial reporting. A probabilistic output in those processes means results could vary for the same input, making them impossible to audit, reconcile, or trust.
In contrast, LLMs are excellent at tasks that require interpretation, context, or language understanding.
Where LLMs fall short
LLMs are unsuitable for tasks requiring exact, repeatable results like payroll or medical dosages. Their probabilistic nature introduces risks that prompt tuning cannot fully eliminate.
Cost is another factor. Unlike traditional rules with near-zero marginal costs, LLMs incur recurring per-token fees that compound at scale. Using them for problems that can be solved with deterministic logic is unnecessarily expensive.
Integration may be easy, but LLMs should be reserved for unstructured data, language interpretation, or high-variation inputs where static rules fail.
Selecting the right approach
Choosing between LLMs and deterministic logic depends on the task. For support tickets, LLMs excel at interpreting sentiment and categorizing issues, while deterministic logic is better for precise tasks like calculating SLA breaches or routing by priority. Combining both provides flexibility for messy data and precision for exact outcomes.
LLMs bridge language gaps by extracting entities and normalizing unstructured data like emails or PDFs, reducing manual effort. They also serve as flexible middleware, adapting to changes in the source and minimizing the need for pipeline rewrites caused by data drift.
Real-world use cases: Where LLMs add value in data workflows
Not every ETL task benefits from an LLM. The clearest wins come when data is unstructured, inconsistent, or requires interpretation that rules cannot provide.
Classifying support tickets
Raw support ticket exports often contain free-text conversation history with no consistent tagging. An LLM can export conversation history from platforms like Zendesk, read tickets, and automatically classify them as product defects, user errors, billing issues, or feature requests.
This approach replaces manual tagging and removes the need for exhaustive keyword lists that quickly become outdated.
For example, one fintech company processing 400–500 support tickets per day found that manual categorization was causing delays and frequent misclassification. After introducing an LLM-based classification system that analyzed ticket text and its semantic meaning, the system achieved around 80% classification accuracy.
Intelligent entity resolution
Merging records across different systems is a common challenge in ETL processes. Customer names may be spelled differently. Company names are abbreviated (International Business Machines, shortened to IBM). And addresses are formatted inconsistently, like "Jon" at "123 Main St" versus "Jonathan" at "123 Main Street, Apt 1."
Fuzzy-matching algorithms can help, but they require significant tuning and still produce errors at the edges. An LLM can reason about whether two records refer to the same entity by interpreting context rather than just comparing strings.
For example, recent research combines LLM reasoning with retrieval systems to resolve entities across noisy datasets, such as census records or administrative databases. These systems can identify variations in names, addresses, and relationships while maintaining traceable decision logic.
Contextual extraction and tagging
ETL pipelines may have to pull information from emails, PDF contracts, and internal Slack logs. These sources can contain dates, dollar amounts, party names, obligations, deadlines, and other information in natural language.
LLMs can reliably extract these fields without requiring a custom parser for each format, since they are well-suited to contextual extraction. Pairing them with structured pipeline logic helps ensure consistent, accurate results across varying document formats.
Anomaly detection with explanation
Traditional anomaly detection flags records that fall outside expected ranges or patterns, but they cannot explain why a data point (record) looks unusual or what it likely means.
For example, it might flag an invoice where the line-item total does not match the billed amount. However, it cannot tell you whether that gap looks like a currency conversion error, a duplicate entry, or a missing discount applied upstream.
An LLM integrated pipeline can detect and describe the inconsistency in plain language, so that downstream teams can investigate and resolve issues faster.
Automated transformation logic
Engineers can use LLMs to generate SQL snippets, mapping rules, or transformation scripts from business requirements written in plain language.
This speeds up development cycles and helps translate business intent into pipeline logic without a lengthy back-and-forth between analysts and engineers.
Integrating LLMs in ETL architecture: Key patterns and considerations
Adding LLMs to an ETL pipeline requires architectural decisions that affect cost, reliability, and compliance.
The multi-model approach
No single LLM provider is the right choice for every use case or every organization. Models differ in cost, performance, data residency terms, and availability. Pipelines designed to work with a single provider create lock-in and limit your ability to adapt as the model landscape evolves.
Also, the AI model space changes quickly, as the model that is best-in-class today may not be in the future. Organizations can switch between managed services, such as OpenAI, Claude, or Gemini, and open-source models, such as Llama 4 or Mixtral, as their needs change. This flexibility allows them to maintain a model-agnostic architecture.
Cloud services versus locally hosted models
When integrating AI, you need to choose between the trade-off of reasoning power and data control (governance).
There are two main options:
-
Third-party managed APIs: These are well-suited to high-reasoning tasks where your data can leave your infrastructure perimeter, and you want access to the latest state-of-the-art (SOTA) models without managing hardware. They offer fast deployment and strong out-of-the-box performance.
-
Locally hosted or self-managed models: These are the better fit for privacy-sensitive or regulated workloads. If your data includes personal information, financial records, or intellectual property that cannot be shared with an external API, running a model in-house allows you to maintain control over data residency and ensure compliance. Additionally, in-house processing helps you predict costs more accurately. Tools like Ollama let organizations run open-source models on their own hardware.
The choice often comes down to the sensitivity of the data being processed. Many organizations use both, routing non-sensitive enrichment tasks to cloud APIs while keeping sensitive transformation steps on-premises.
Hybrid flows
A common architectural mistake is to attempt to use a large language model (LLM) for every step of a transformation process. Running LLM inference on each record can be expensive and slower than using deterministic logic.
The most efficient pipelines use LLMs only when genuinely needed. Filtering, sorting, deduplication, and schema mapping can all be handled by traditional components.
LLMs are reserved for the steps that require reasoning, interpretation, or language understanding. It keeps costs manageable and performance predictable.
For instance, a pipeline might use traditional SQL to identify the top 5% of suspicious transactions, and then use an LLM only to describe the nature of those specific anomalies.
Best practices for reliable and governed LLM pipelines
LLMs introduce variability that traditional ETL does not have. Outputs can shift with model updates, prompts can produce different results under similar conditions, and failures in external API calls need to be handled gracefully.

Key pillars of managing and optimizing LLM pipelines
Best practices to address common operational challenges
Governance and traceability:
Log every LLM prompt and its corresponding response. This creates an audit trail that is essential for debugging, compliance reviews, and understanding why the pipeline produced a particular output. Without this, diagnosing issues becomes guesswork.
Data privacy control:
Mask or tokenize sensitive fields before sending data to any external model. Personal identifiers, financial data, and health information should never leave your environment unless explicitly permitted by your compliance framework. Apply these controls at the pipeline level, not as an afterthought.
Performance management:
LLM API calls are slower than in-memory transformations. So, monitor latency, manage concurrency to avoid rate limits, and implement retry logic and fallback behavior for failed calls. A single unhandled timeout should not bring down an entire pipeline run.
Continuous refinement:
Prompts degrade over time as data patterns shift and model behaviour changes with provider updates. Build feedback loops into your workflow to identify where the model produces low-quality outputs and update prompts accordingly.
Cost optimization:
Token usage quickly adds up at scale. Use batching to reduce API calls. Cache results for identical or similar inputs when suitable. Track token usage across pipeline components to spot and fix inefficiencies before they lead to high costs.
How CloverDX helps implement governed LLM pipelines for ETL
The best practices mentioned above are easy to list but hard to apply consistently at scale. CloverDX addresses this by treating LLM calls as a first-class ETL component (AIClient), with reliability controls and enterprise logging and monitoring baked into the same runtime.
Model-agnostic AIClient
The CloverDX AIClient component connects the data pipeline to the LLM. It allows engineers to compose queries, manage chat context, and process responses using the platform's native CTL (CloverDX Transformation Language).
Because it is model-agnostic, the same component can be configured to connect to Anthropic, Google, Azure, or locally hosted Ollama instances, and prevent vendor lock-in.
The AIClient is designed for reliability with built-in attributes for:
-
Retry Count and Delay: Automatically handles intermittent API failures.
-
Rate Limiting: Ensures the pipeline stays within the provider's throughput limits.
-
Request Timeout: Prevents the entire job from hanging if a model is slow to respond.
Local and on-premises AI model support
CloverDX supports the deployment of AI models locally (on a secure cloud environment, too) within private infrastructure. It enables sovereign AI, which is crucial for securely testing transformations on sensitive data (PII, healthcare, financial) while maintaining 100% privacy and compliance.
The CloverDX Marketplace offers several ready-to-use local models for:
-
PII Classification: Identifying sensitive data for governance.
-
Sentiment Analysis: Detecting positive or negative tones in customer feedback.
-
Zero-Shot Classification: Categorizing text into user-defined topics without pre-training.
Seamless pipeline integration
The AIClient can be embedded directly in CloverDX transformation graphs. Engineers can configure prompts, handle multi-turn responses, and map model outputs to existing schemas within the same visual workflow environment used for traditional ETL. There is no separate system to manage.
Automated governance and security
CloverDX ensures every AI decision is traceable and auditable via built-in logging of LLM interaction metadata. Security is maintained through credential isolation, preventing API key exposure. Its data privacy by design approach includes local anonymization pre-processing, so only secure text is sent externally.
Take CloverDX for
a test drive
Explore every feature that CloverDX has to offer and experience the difference for yourself.

Building ETL pipelines that can evolve with LLMs
LLMs move ETL from simple data transport to active data understanding. They help work with human-generated data at scale, without the maintenance burden of thousands of edge-case rules.
Production pipelines will fail without proper controls, logging, and monitoring, especially when relying on single providers or sending sensitive data externally. Organizations achieve value by applying the same engineering discipline to AI steps as to the rest of the pipeline.
Future-proofing data strategy requires building flexible, multi-model infrastructure from the start to easily adapt as models and new deployment options emerge, avoiding major rearchitecting.
Start building smarter, privacy‑first ETL pipelines today by integrating LLMs with CloverDX.
Share







