Data Integration Platform
The flexibility to handle the most complex data workflows
Reduce manual work, increase visibility and reliability, and make data processes more accessible for business users.
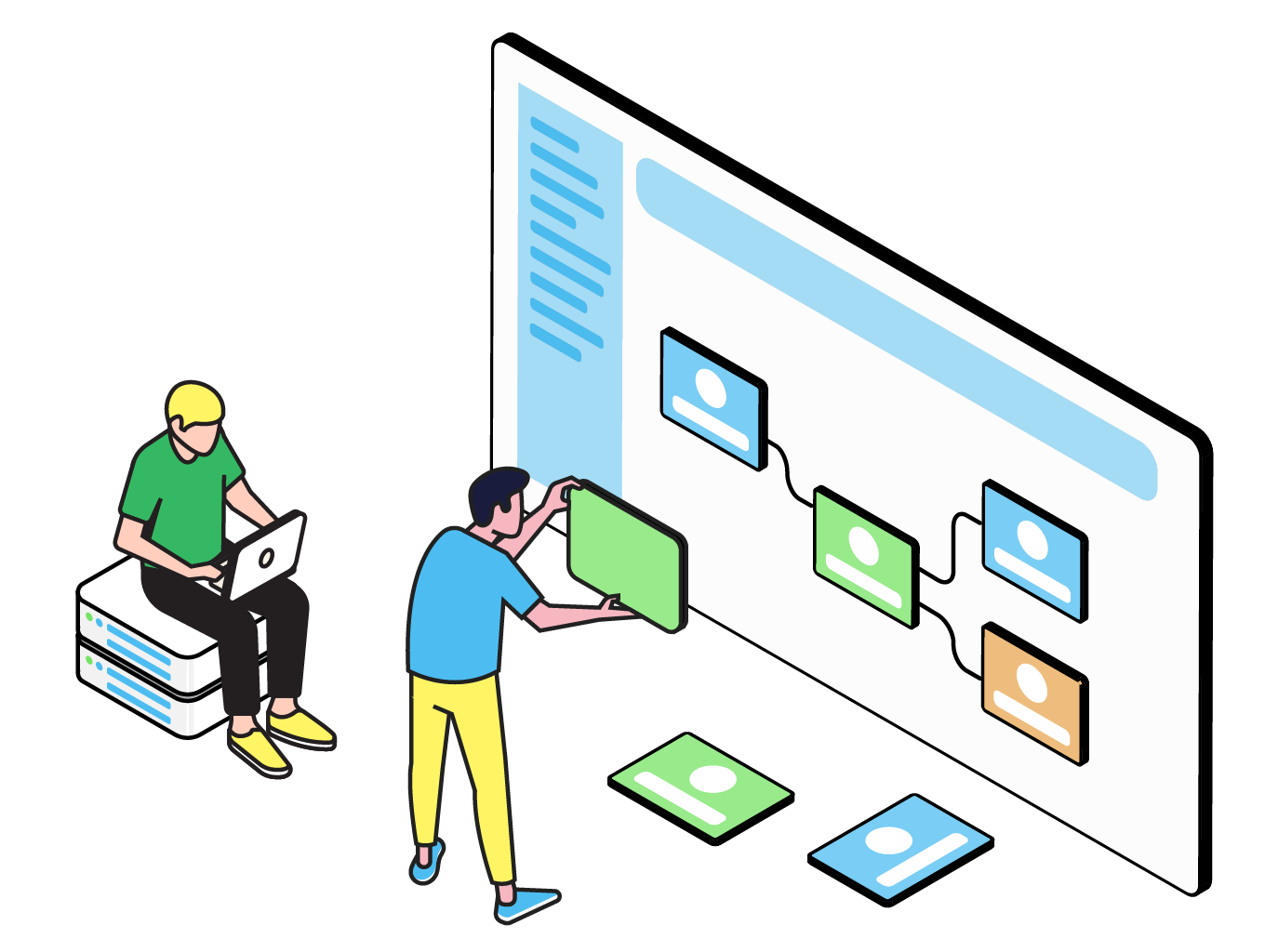
Ingest
Ingest data from any source
Connect to any data source – cloud or on-prem – with CloverDX’s agnostic approach, and build end-to-end reliable, automated data ingestion pipelines.
- Connect to any source – either with out of the box connectors, or build your own.
- Extract and transform any data formats.
- Maintain data quality with automated, always-on validation and error handling.
- Flag and assign records that need additional manual review.
- Automate the entire end-to-end process to run on autopilot.

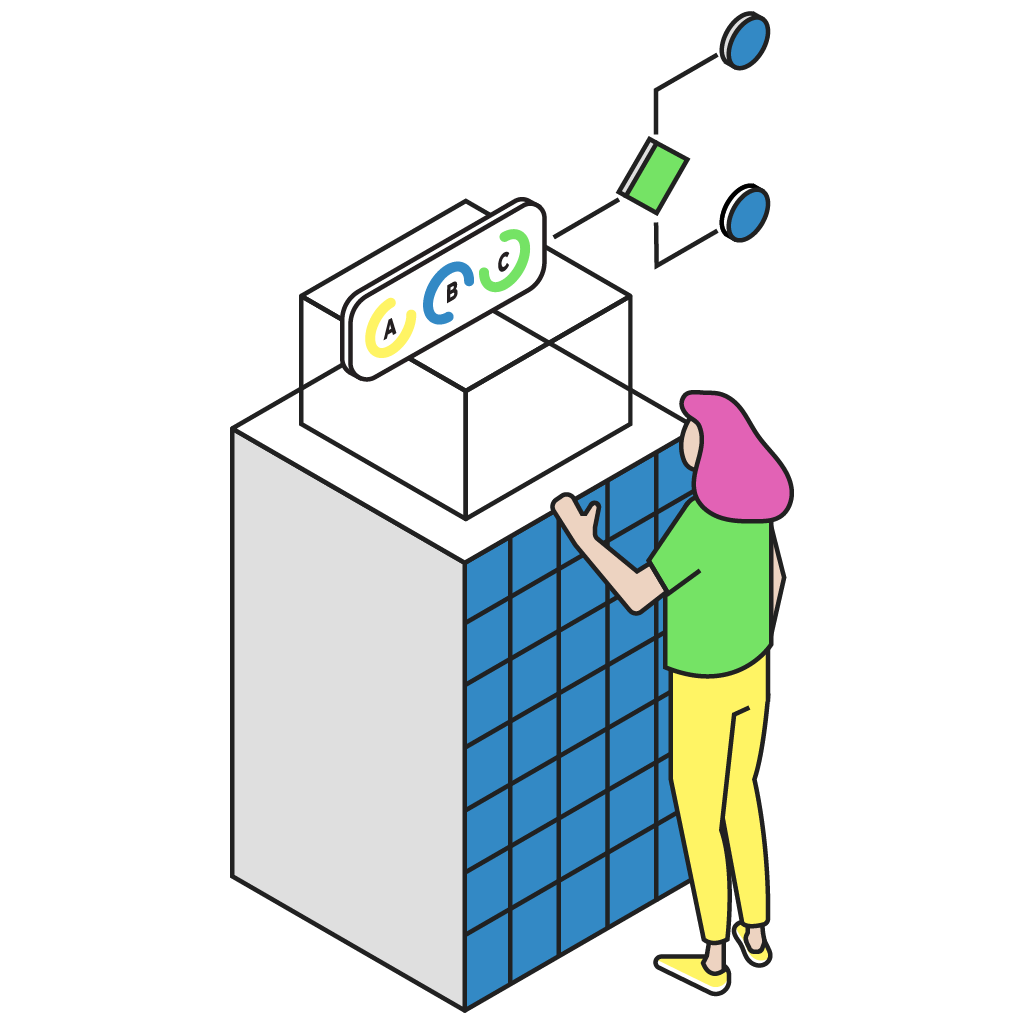
Master Data Management
Let data owners manage shared reference data directly
Master data management can be complex, but CloverDX simplifies it by providing the essential tools for centralized reference data management. This ensures that developers can confidently rely on accurate and consistent data, while data owners maintain full control over the management and governance of their data assets.
- Give domain experts power over data quality and ease the burden from data engineers
- Manage shared reference data that can be used across the organization.
Data Quality
Add manual quality control into your pipelines
Automated validation is essential for any data pipeline. However, sometimes it can't handle complex situations. To ensure complete trust and data quality, human operators must step in to review, correct, or approve the data for further processing.
- Manually intervene in pipelines to review, edit and approve incoming data.
- Achieve 100% trust in data by combining always-on validation with human inspection and intervention when necessary


We would get a price file… and to load it into our ERP system would take three to four days. Now with CloverDX I believe it takes us about three hours to process through the million records.









See how CloverDX could help solve your tricky data problems
Book a demo of CloverDX and see how you could reduce manual work, increase reliability, and improve collaboration, with even the most complex data problems.