You’ve got a simple task – move some data or prepare it for use. It seems like a pretty quick job, so you solve the problem with some Excel, or maybe some scripting. Job done, right?
But over time the simple task may have revealed itself to be…. not so simple. It’s maybe evolved to be more complex, or perhaps it’s become too crucial to the business to be handled casually. Maybe it’s time to consider moving on from homegrown ETL solutions to something more robust and reliable that will enable you to handle more data, more easily.
This post is based on a recent webinar on Automating Data Pipelines. You can watch the full video here, or read the post below.
What do we mean by homegrown ETL solutions?
When we talk about ‘homegrown’ or DIY ETL solutions, we mean something that’s been designed and developed in-house to solve a particular data problem. It’s often a combination of several things:
- Manual process: Your ETL solution might begin life as just a set of manual processes. Grab some data from a source; drop it into Excel; do some magic with copy/paste, text-to-columns, formulas, or Vlookups; export the result to CSV and pass that along to some other process or data endpoint.
- Scripts: Or you might have a power user skilled with scripting, using a shell, Excel macros, Python or SQL, and they can write code to shape, map and prepare data.
- Custom applications: Larger companies might have in-house IT departments who can build custom solutions to address specific requirements.
There are very understandable reasons you may have originally decided to use any of the above approaches:
- Naïve assessment of the task: It may have seemed like a simple task at the outset
- Urgency: Maybe there was a tight deadline and you didn’t have the time to research or go through the buying process for a third-party tool
- Exceptional requirements: You might have thought that your requirements are too challenging for an off-the-shelf solution to handle
- Exceptional team: Maybe you had a highly skilled dev team already – they understood the project and they’re eager to build something bespoke
- Habit: Or it could be that this is the way you or your company has always done these projects
But at some point these DIY solutions might start causing problems. Some might be manageable, but some might be posing risks to your business.
Modernize your data processes with CloverDX: See how you could save time and eliminate riskThe risks of homegrown data scripts
Homegrown scripted data processes can pose risks in several different areas:
- Not being able to keep up with increasing volumes of data: When scripted processes take so long to run, and often have issues that cause them to fail, your users can be left without the data they need.
- Ad-hoc solutions that might stop working: When the business is relying on a scripted process, it’s vulnerable to changes that are out of your control. We had one customer who came to us worried about Excel’s increasing restrictions on macros and VBA, given how much their organization relied on Excel-based data processing. As he described it, “If Microsoft turned off that VBA, our finance department would be in tears. They wouldn’t be able to do their job.”
“If Microsoft turned off that VBA, our finance department would be in tears. They wouldn’t be able to do their job.”
- Wasting time on repetitive tasks: Processes that might not even be very complex can take up a significant amount of time. A couple of hours on a report every week add up quickly when there are multiple reports to prepare.
- Lack of visibility into errors. It can be hard to know if your data is reliable. Often, the first indication of a problem with a scripted solution is when the end user reports a problem with their data. (That’s if they even notice – what often happens is no one realizes that e.g. a particular source isn’t working, so the analysis is unknowingly using incomplete data).
- Tricky troubleshooting: Assuming someone has realized the data is wrong, it’s often time-consuming and frustrating to figure out where the problem lies. There can be a lot of combing through logs, and even then it’s not always apparent where the error occurred, so it takes even more time to try and reverse-engineer the issue.
- A key person leaving the company: When processes have been built and maintained by one person, the knowledge about how things work or why they were built a particular way often only exists in their heads. If they leave the company, the business can be in a tricky spot (and the data process becomes even more unreliable because everyone else is too scared to touch it).
Often this situation reaches a tipping point where the time required to manage the process, the unreliability of the data, or the risk to the business becomes too much. But how do you know when you've reached this point?
How do you know when your homegrown solution is no longer meeting your needs?
How to spot when it's time to upgrade your data pipelines
There are several warning signs or triggers that might make you realize you’ve outgrown your older decisions, and you need to explore more robust, reliable solutions.
- Feature gaps: You need new features that are hard – or impossible – to build. Or the endpoints the solution interacts with may have evolved – what used to be in Excel is now in a database for example. Or new data quality constraints may have come into play.
- Lack of transparency: You need more information about how the solution is operating, and better visibility over whether things are running reliably and on time.
- Age: Maybe your ETL has accumulated too much technical debt, or the systems it runs on are becoming obsolete.
- Maintenance costs: The costs – direct or indirect - of keeping things running are increasing. Maybe the dev team has other projects they should or could be working on.
- Scaling issues: Needing to meet increased demand is often a driver for seeking a more robust solution.
How a data integration platform can help
Using a data integration platform to replace your scripted or Excel-based data processing can eliminate a lot of the risks you might be facing, and bring several benefits.
- Fully automate your jobs – run full end-to-end processes on a schedule, on a trigger (e.g. files arriving in a certain location), or at the click of a button, giving you flexibility and saving time.
- Better visibility – a platform that enables visual design makes it easier for everyone to understand what’s happening with the data process.
- Instil confidence – monitoring, automatic error alerts, detailed logs, and full visibility into exactly where problems occurred makes your data more reliable and troubleshooting much faster.
- Free up significant time – spend less time on manual, repetitive tasks and painful troubleshooting, and focus more on higher value activities.
- Enable less technical staff to work with data jobs – a data integration platform can make it easier for non-technical users to operate and use data jobs, without having to deal with the complexity of the IT side.
Case study of an automated data pipeline in a data integration platform
This example is a real-life solution of a FinTech customer using CloverDX to ingest data. They receive data from multiple clients on a regular basis, and each one has a different format that needs to be transformed and loaded into the warehouse.
The manual option
Of course, it's possible to do all of this manually - grab files from an FTP program, open them in Excel, visually inspect them, clean up the data, maybe remove, split or merge some columns, and use a data import wizard to get them where you need them.
But this quickly becomes impractical. Huge data files, too many files, needing to do it too frequently – doing it manually isn’t really an option at any kind of scale.
You could use scripts to handle these tasks – and maybe more scripts to stitch each step together. Still quite ad-hoc and error-prone, as well as not being very transparent. And although it saves some time, it still takes up some resource.
Or you could use a data integration platform and take people out of the loop completely. You can automate the entire process, monitor it all and alert people to errors that need intervention. You save significant time, remove sources of error, and get complete transparency.
Let’s look at how this process works in CloverDX.
We want to automate the whole end-to-end process of these steps:
- Detecting arrival of client files to be processed
- Detecting format and layout of client files
- Reading files
- Transforming/mapping
- Assessing quality
- Loading to target
- Detecting/logging at every step
And we want a reusable process. The ideal is a single generic job that can be used for many situations, not creating a new version of the job every time you want to ingest data from a new client.
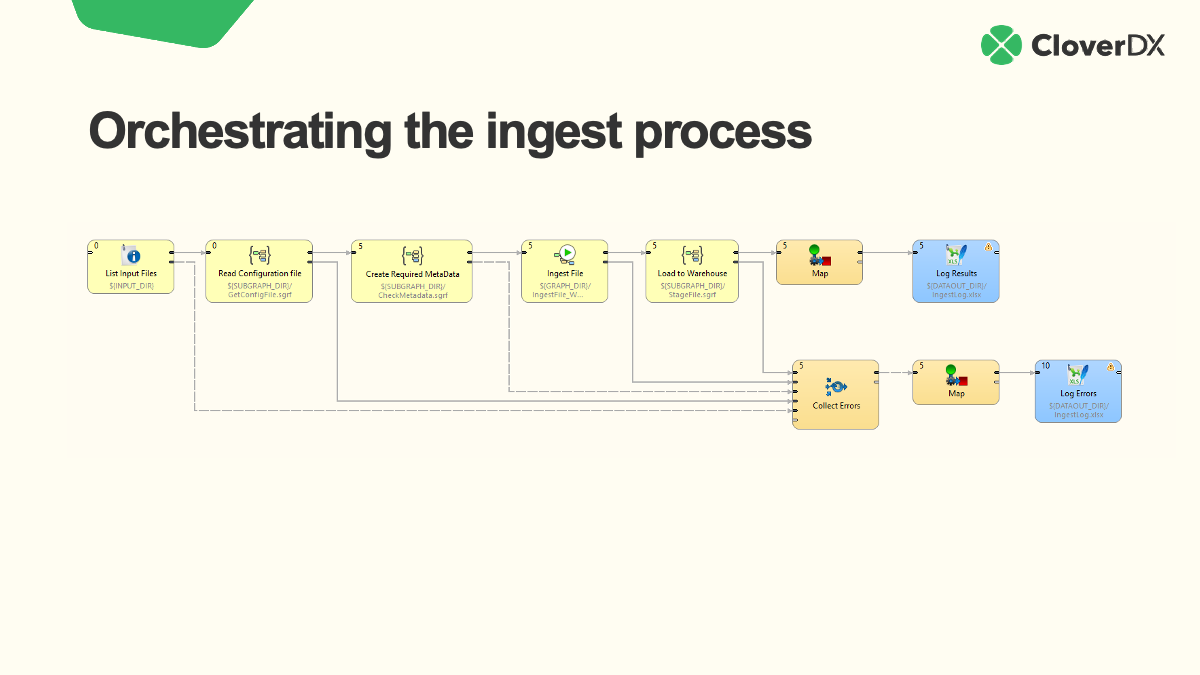
This is what that pipeline looks like. It handles every step, and captures errors that occur at any stage. You can run multiple files through the pipeline, and collect info on any that are rejected (and even handle those rejected files automatically).
The Ingest File process in more detail
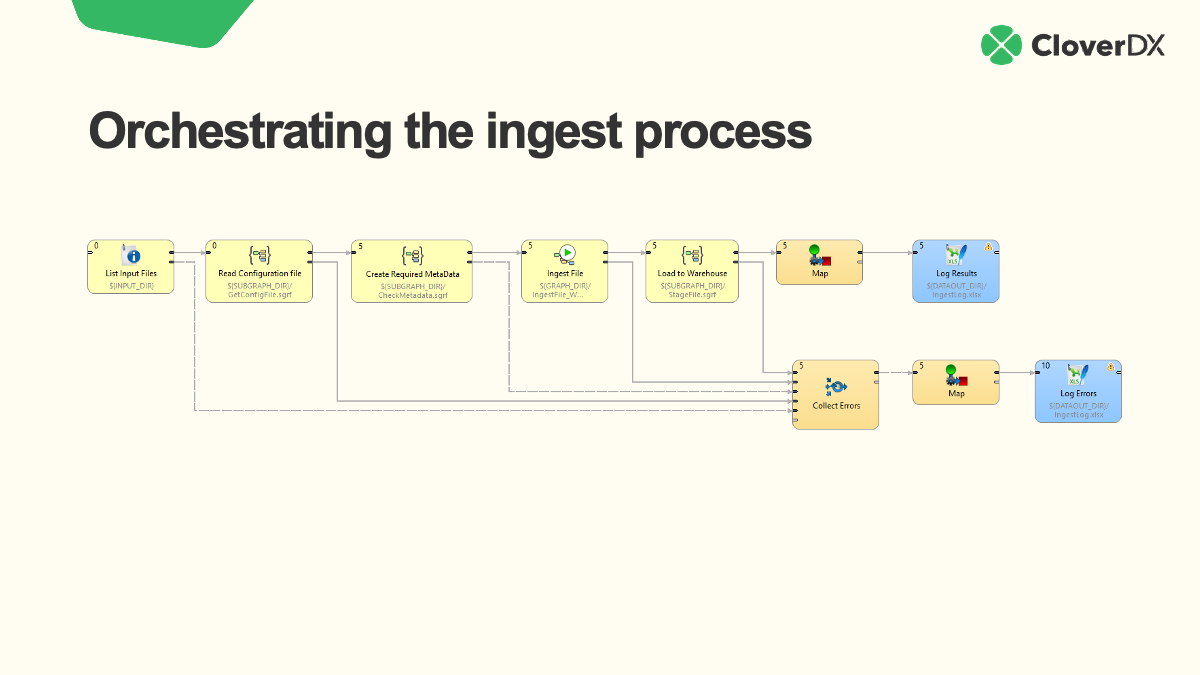
This is what the Ingest File component, which handles the record level processing, looks like when we drill down into it. If you were doing this manually, this is the activity you’d most likely be doing in Excel.
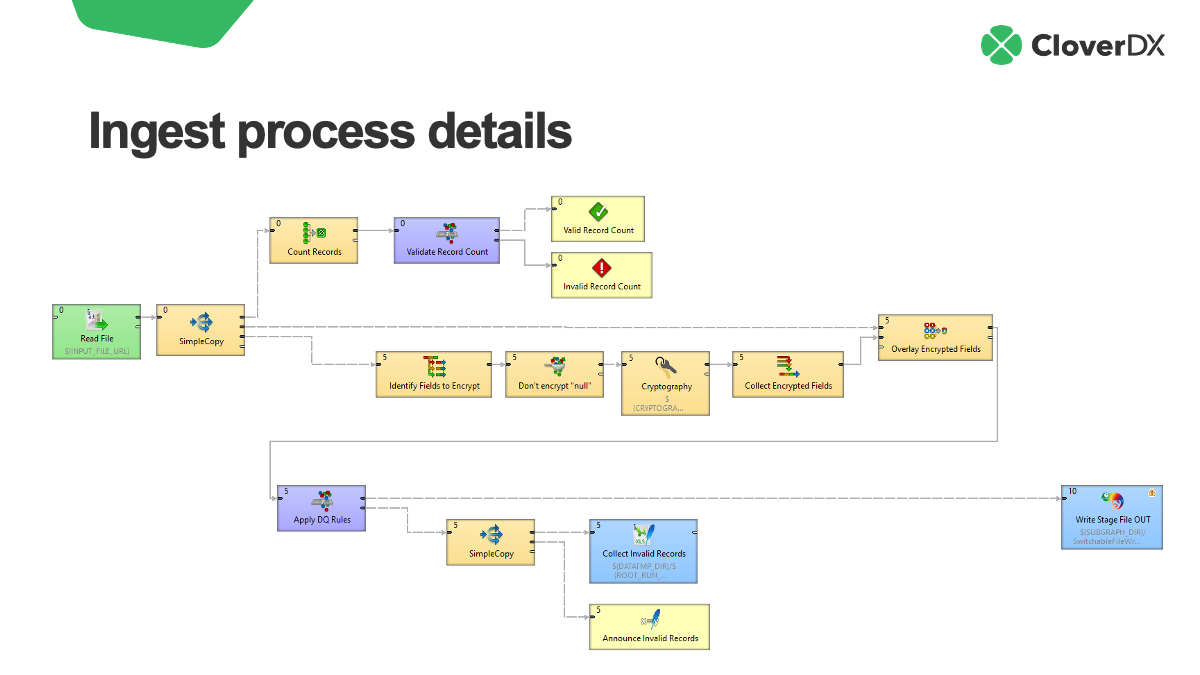
This is what this part of the process is doing:
- Read the file
- Make sure the record count is what is roughly what is expected. If not we can fail the file and/or alert someone to the error.
- Encrypt or mask certain fields
- Apply a set of data quality rules (filtering our records that are suspect)
- Collect those invalid records so that can be addressed
- Ultimately to create a newly shaped file that is ready to load into the warehouse
You could do all this in Excel, or a script, but the visual nature of this job allows us to see every step - much easier than trying to understand the process by looking at an Excel workbook.
Data validation in CloverDXAutomation of data processes in CloverDX
This all becomes even more valuable when you run jobs automatically and unattended – whether scheduled, triggered by a specific event, or launched on demand (e.g. via an automatically generated API endpoint, triggered via a simple user interface).
And you get full visibility over all activity – alerts for failure, logs of every execution, and graphical inspection of a run to see exactly where the job failed and why.
If you want to discover more about how you can automate your data pipelines and move on from scripts and Excel, request a demo of CloverDX and see how you can eliminate business risk and save time and money.
How setting up a data ingestion framework helps automate and speed up customer data onboarding
Share







