
Automating the customer data onboarding process means you can onboard more customers, more quickly, without needing to tie up (or hire more) expensive engineering resource.
We’ll walk through how a data onboarding pipeline in CloverDX works, and how it can handle your data onboarding on autopilot, no matter how many different clients you’re receiving data from. You can watch CloverDX Director of Solutions Engineering Kevin Scott explain the process in this video:
What does a good customer data onboarding process look like?
We want our automated data onboarding pipeline to be a complete process – that handles the onboarding from start to finish, including handling errors and exceptions. It needs to manage every step:
- Detect that new data is available to onboard
- Inspect the layout and format of that data
- Read the data
- Map and transform data
- Assess data quality
- Loading data to target
- Detect issues and log progress through each step
And a good data onboarding pipeline is reusable – a single generic data job should be able to be used for many clients, as opposed to creating a new version of the process every time you need to ingest data from a new customer.
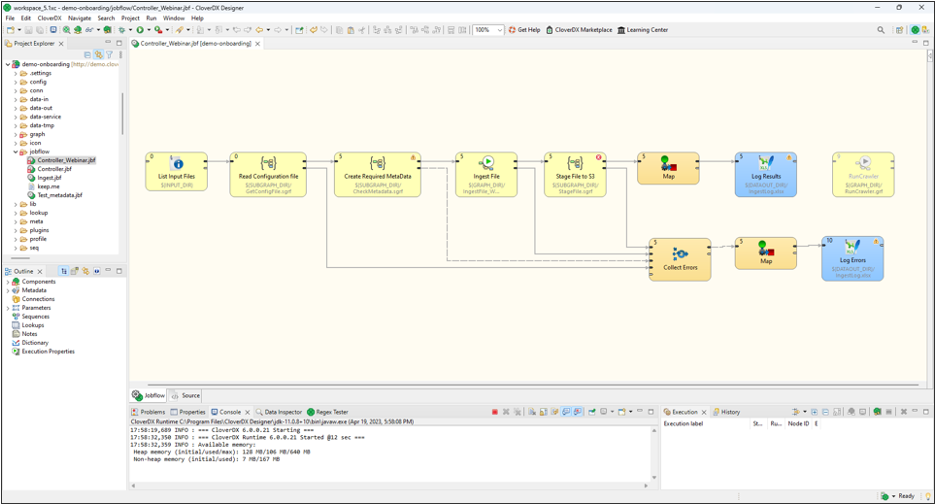
And this is what the process looks like when it’s implemented in CloverDX. This is an example of a data onboarding pipeline that we implemented for a finance client, to take in data from their customers, transform it in accordance with specific rules for each customer, and ingest it into the finance client's platform.
Each of the boxes contains all the steps needed for that particular part of the process.
A data onboarding pipeline in CloverDX
Driving an automated data onboarding pipeline with configuration files
In this particular pipeline, we are matching a clients’ data with a specific configuration file so that we can onboard the data automatically.
In these two steps of the pipeline we’re detecting the data, and once we have that data we’re looking up a configuration file to give us instructions as to how the rest of the pipeline should behave.

Reading the configuration file to drive the data pipeline
This is a key practice for developing a single pipeline that can work for many clients – holding all the client-specific detail in configuration files. When you extract that client-specific detail out of the pipeline and into some external configuration file, the pipeline becomes essentially a generic processing and orchestration framework.
Want to see this process in a demo?
Request a demo of CloverDX and one of our engineers can walk you through an automated customer data onboarding pipeline and answer any questions.
This configuration can be stored virtually anywhere – flat files, database tables – we often use Excel, for several reasons:
- It's human readable
- We can share this document with the end client – they can see what we’re planning on doing with the data and make it easier to collaborate on fixing any issues
- Allow less technical staff to modify and operate the pipeline
This is an example of a config file that we used in this pipeline:

Configuration file with metadata about the client sending the data
You can see that in the first tab we have some metadata about the client that’s sending the data – their name, ID, contact info, expected arrival times etc.
The second tab in the file has the meat of the mapping – the fields we expect to be in the data, their types, and some rules about how to treat certain fields - such as whether we should encrypt certain fields, or whether we should allow nulls.
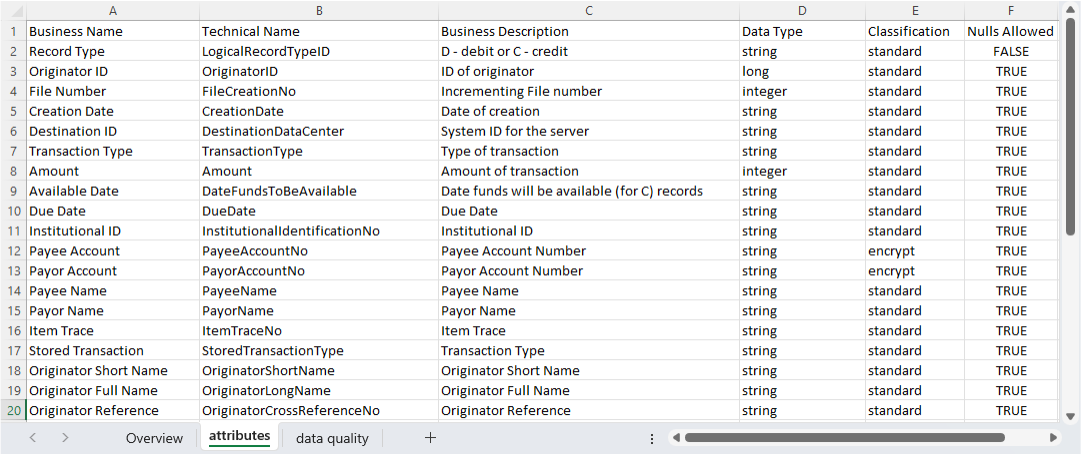
Configuration file with data mapping information
The last tab on the configuration has the client-specific data quality rules that the pipeline performs when it runs:
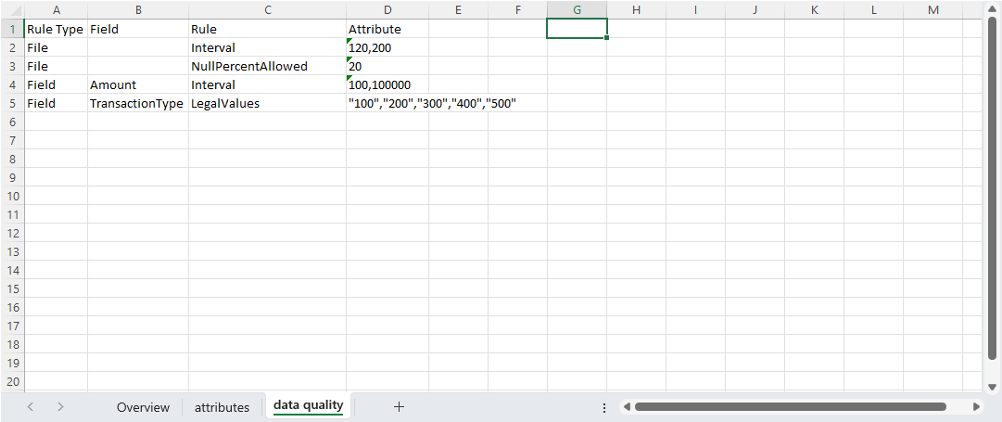
Configuration file with client-specific data quality rules
The benefit here is that the customer can easily understand these rules, and CloverDX can also translate these into instructions to implement in the pipeline at runtime.
These rules can be either at the file or field level, and they give us all the information we need to be able to onboard a specific customer data set.
Case study: How Zywave freed up engineer time by a third by automating customer data onboardingThe next step is the ingestion – reading and processing the data and getting it into our system.
The single Ingest File component of the original pipeline can be drilled down further into individual steps. When we break that component down we can see the detail:
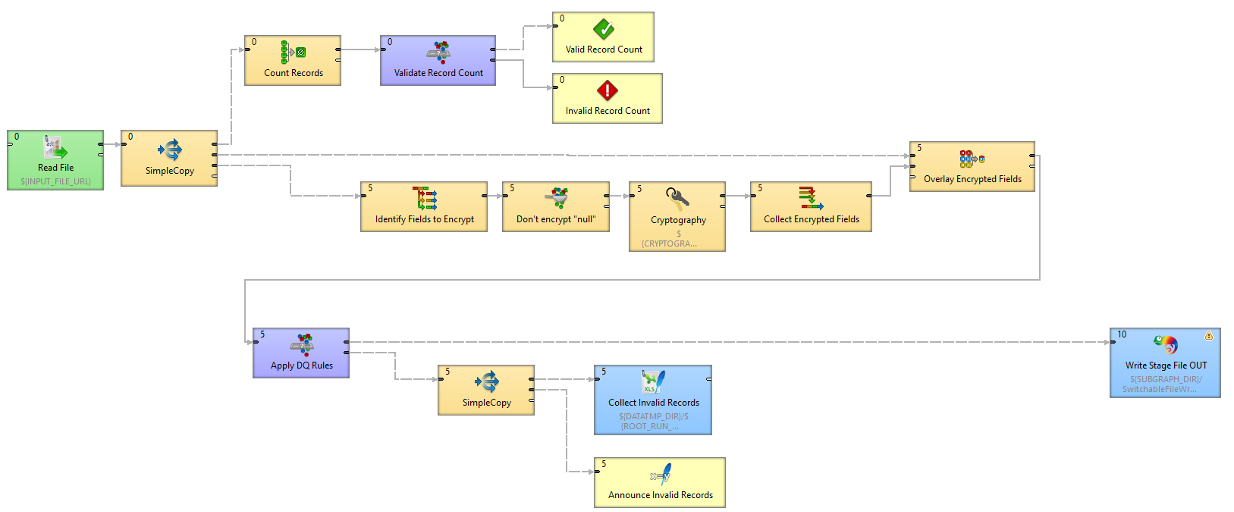
Detail of the ingestion part of the data pipeline
This process covers not only the ‘happy path’ that we want to follow (read the file, do the transformations, do the quality assessments and output it) but also sections to detect and deal with any errors, and log all the data that is flowing through.
The pipeline also:
- Reads the file - in a generic way, without needing to know in advance what the incoming file it. The information the pipeline needs has been extracted from the configuration file and used to configure the reader component so it knows what it's supposed to be expecting.
- Counts the number of records to make sure it’s roughly what we’re expecting (again, set at a per-client level) – if not we’ll stop the process.
- Performs the data transformation – including encrypting certain fields.
- Validates individual fields to ensure data quality, including checking against the rules required for the particular platform we're ingesting into, also any client-specific rules for this dataset.
- Logs any records that fail these checks, and creates a human-readable file with details of these records and the reason they failed, so we can fix them and re-run the pipeline easily (crucially, without needing a developer to step in).
The whole process operates in production on CloverDX Server. You can run these jobs automatically and unattended, and they'll be monitoring and logged, as well as alerting you to any errors.

What is poor data maturity costing you?
You may not notice it day to day. But manual fixes, rework, and brittle pipelines have a price.
Complete the State of Data Maturity survey and get a practical benchmark in about seven minutes.
Automating data onboarding jobs in CloverDX
Jobs can be run on a schedule, in response to a trigger (such as files arriving on an FTP site), or run whenever you need to through an API endpoint that CloverDX automatically generates.
You can set up web interfaces that allow non-technical users to run the jobs, and even enable them to upload new configuration files if necessary, without ever needing to touch the main ingestion pipeline. This is especially useful when it comes to correcting errors – it’s simple to re-run the pipeline on a corrected record set.
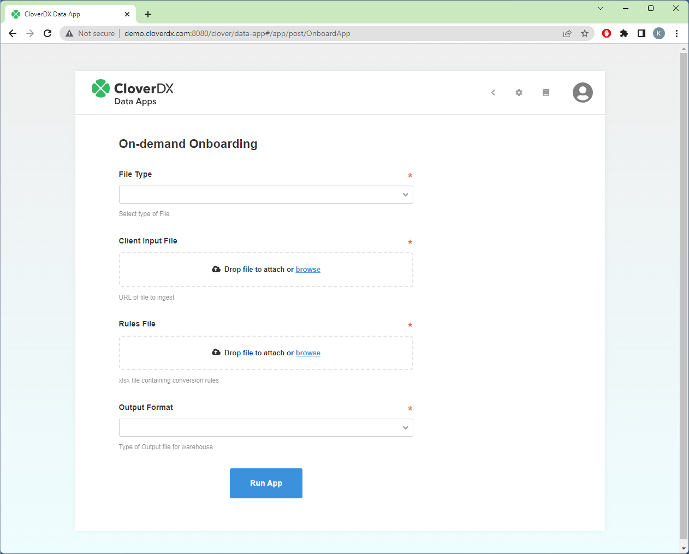
A user-friendly web interface (a CloverDX Data App) to operate the onboarding pipeline
CloverDX Server monitors all jobs, and gives you information at a glance of any problems. You can drill down into detailed execution history – when, where and why the job failed, making it easy to triage and diagnose issues.

Visibility into errors in the data pipeline
Benefits of automating customer data onboarding
By creating a single customer data onboarding pipeline that runs automatically to ingest and transform data, regardless of format or quality, you free up significant time and resource, which in turn saves significant cost.
By using Excel-based configuration files and transparent, visual pipelines you open up the possibility of enabling less-technical users to manage the customer onboarding process, without needing to wait for IT resource.
For your business, this means you can:
- Onboard customers more quickly: No need for the engineering team to be a bottleneck to getting customers up and running. The faster customers can start using your platform, the faster they can realize value, and you can recognize revenue.
- Free up engineering resource: No need for highly technical teams to build a completely new onboarding process for each new customer, so their time can instead be spent on higher-value activities.
- Make life easier for your customers: No need for customers to spend significant time and money trying to format their data to fit your requirements. Instead you can take and work with whatever they have - a great addition to your value proposition.
To see how you could speed up your customer data onboarding or data ingestion process, just request a demo here. We'll get right back to you and talk to you about your specific requirements, so we can show you exactly how CloverDX could work for you to save you time and money.

Share







