When you're onboarding customer data into your platform, you're performing the same actions every time, but there's often important variances in what your clients are sending you.
You could ask your customers to send their data to you in a format that exactly matches what your system requires, but that's often time-consuming and frustrating for them (and can sometimes be impossible if they don't have the necessary technical skill).
Or you could build a data ingestion framework that will handle data in whatever format it's submitted, reducing the burden on your clients. That framework can also empower your less-technical staff to manage data onboarding, and enable you to create a repeatable onboarding process that you can adjust to support the small but important differences between multiple clients.

To examine this in more detail, let’s take a look at three real-world use cases where we worked with clients to build data ingestion frameworks in CloverDX that enabled them to automate and speed up their data onboarding.
Each of these case studies shows how the data ingestion workflow can be designed for resilience, to handle variability in input format, and to manage the whole process automatically - from detecting arrival of incoming files, to ingesting the data, and providing robust reporting and error-handling.
What are the features you should look for in your data ingestion tool?Data ingestion frameworks: 3 real-world case studies
1. Onboarding customer data to a legal SaaS platform
Our client had ambitious objectives for getting data into their legal case management platform.
Requirements for the data ingestion framework:
- The data ingestion framework needed to handle data in a variety of formats and - crucially - without having to know in advance what the format was.
- The client wanted to land that data into staging tables in a relational database.
- And they also wanted to simplify re-tries, without the need for support from the technical team.
Here is a visual representation of the onboarding process they wanted to achieve:.png?width=1360&name=Untitled%20(7).png)
And here’s this process visually represented as a workflow in CloverDX Designer. You can see how designing data pipelines using CloverDX keeps the process in line with the original onboarding objectives:
.png?width=1315&name=Untitled%20(8).png)
Benefits of using CloverDX to build an automated data ingestion framework:
- Input files are automatically detected
- The client can inspect and auto-detect the structure of the data and populate a stage table, all without the need for transformation.
- They also receive error reports so they can make the necessary adjustments to rerun processes without the need of a development team.
- Reports also tell them how long a run takes, what files are ingested, how many records are created and rejected, and why a run failed. They can then take this information and adjust the metadata to perform a rerun, without having to change the pipeline itself.
The result is faster, more efficient data onboarding and better service for their clients.
Building an automated customer data onboarding pipeline in CloverDX2. Creating a data ingestion framework to onboard data from multiple school locations
Class schedules, enrollment figures, attendance records—schools deal with a lot of dynamic data. They also need to share this data with stakeholders who aren't usually very technical.
We worked with a platform who deal with data from a network of K-12 schools. They had been using a bespoke system in Python, but this was challenging for users, and they wanted a portal that their stakeholders could easily access.
Requirements for their data ingestion framework:
- The ingestion process needed to be handled automatically, so the data they were providing back to their stakeholders could be accurate and up-to-date.
- They needed to receive and process data in a variety of formats, and sent in a variety of ways including via FTP and email, so needed to continually monitor locations for incoming files.
- The entire process needed to be orchestrated to run on autopilot.
- And the framework needed to adapt automatically when a new school was added - without the need to build a new ingestion pipeline each time.
The data ingestion framework built in CloverDX
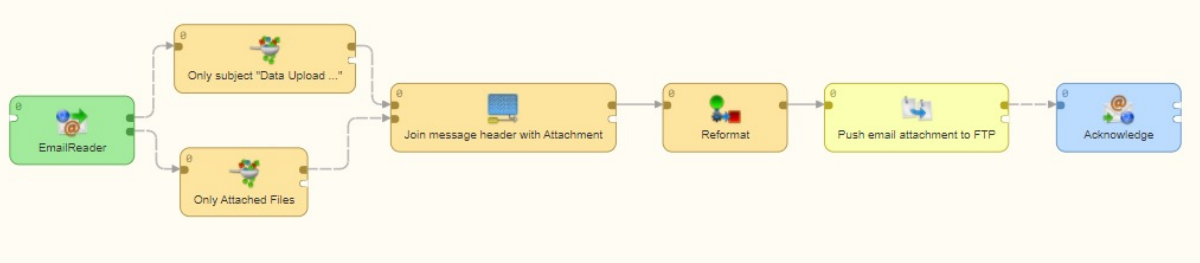
The new data onboarding framework completely automates the platform's data ingestion. It monitors an FTP site to automatically detect and process incoming files, but also automatically scans an email inbox for emails that meet particular criteria:
.png?width=1200&name=Untitled%20(9).png)
These emails are then automatically pushed into the FTP process:
.png?width=1253&name=Untitled%20(10).png)
In fact, CloverDX orchestrates the entire data pipeline including:
- File unzipping
- Quality checking
- Sanity checking
- Data transformation
- Pushing of data to APIs
It also takes the data files and pushes them into an S3 bucket.
What’s more, the pipeline is entirely reusable, so the platform owners don't need to create new pipelines when a new school is onboarded.
3. Onboarding data to a consumer debt collection platform
Our third customer work in the debt collection space, and needed to automate their customer data onboarding to remove barriers to client acquisition.
Requirements for the data ingestion framework:
- Accept data in a variety of formats, to accommodate the ways clients would provide data.
- Enable non-technical users to onboard and update the data, without relying on development resource.
- Automatically look up and implement client-specific mapping and transformation rules, to handle each category of files appropriately.
A data ingestion framework driven by an Excel-based configuration file
We built a pipeline that uses an Excel file to manage data mapping. The non-technical onboarding team were able to define mappings in the spreadsheet, without needing to write code, and the pipeline consults that spreadsheet to implement the mapping.
.png?width=1034&name=Untitled%20(11).png)
The ingestion solution also provides:
- An automatically-generated web app where the non-technical users can upload an input file which triggers the data pipeline to run automatically
- Rich error logging so users can view reports on which records were rejected during the ingestion process (and why), to make debugging and re-running the process easy.
Automated data ingestion frameworks with CloverDX
Although each of these real-world use cases of data ingestion frameworks are slightly different, they all used CloverDX to give them:
- End-to-end orchestration - a completely automated, unattended process to allow new data to be onboarded with no extra effort.
- A system that can handle variations in input. So being lenient in what we accept, without having to stop the data process or burden the client by asking them to change the structure of what they're sending.
- A solution that can be managed by a non-technical team. By using configuration files to drive the underlying pipeline, onboarding teams (who have the best knowledge of the data) can do more of the work themselves, without needing to code or to rely on a development team.
To chat to us about building an automated data ingestion framework to onboard your customer data, just request a demo.
You can watch the whole video of the webinar this post is based on here: How setting up a data ingestion framework helps automate and speed up data onboarding
Share







