
Data validation in your data ingestion process is vital to keep your data pipelines flowing smoothly and to ensure that the data you’re working with is correct and useful.
We outlined some more of the objectives of data validation in this post and here we’ll show you how you can build these validation steps into your pipelines with CloverDX to maintain the quality of the data you're ingesting.
Data profiling and data validation to ensure data quality
Both data profiling and data validation play an important role in managing your data quality.
- Data profiling is a statistical analysis of the data. It gives you a holistic assessment of your entire data set, so not only does it prevent you processing suspect data, but can also help you detect trends in your data, or data quality decay over time.
- Data validation is an assessment of your data at the record level. It involves defining business-specific rules (e.g. all records must have a date, or be formatted in a specific way) so that you can identify records that don’t meet the criteria, and get actionable error messages and fix issues. You can also define what happens to the records, for example continuing to process the good records and rerouting the bad ones.
The data ingestion process with CloverDX
In this example we’ll walk through both the profiling and validation steps in a CloverDX data ingestion pipeline.
This case study involves a platform where multiple schools upload data to either an FTP site or via email and get an analyzed view of that data returned.
The ingest process involves several steps, in a single pipeline:
- Monitoring both sources for incoming files
- Copying incoming files from the FTP
- Unzipping the files
- Checking against a manifest
- Profiling the data
- Transforming it
- Loading to target
- Logging the results
So our basic process looks like this (with the validation steps highlighted):

And we build that out into an executable data pipeline in CloverDX that looks like this:
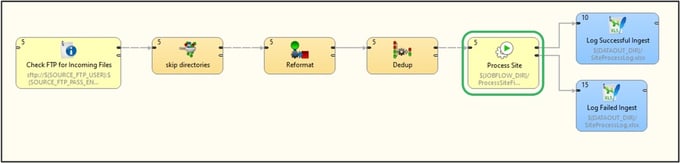
The section highlighted in green above is where we’re performing all those steps, and we can see each individual part of that section by opening it up:
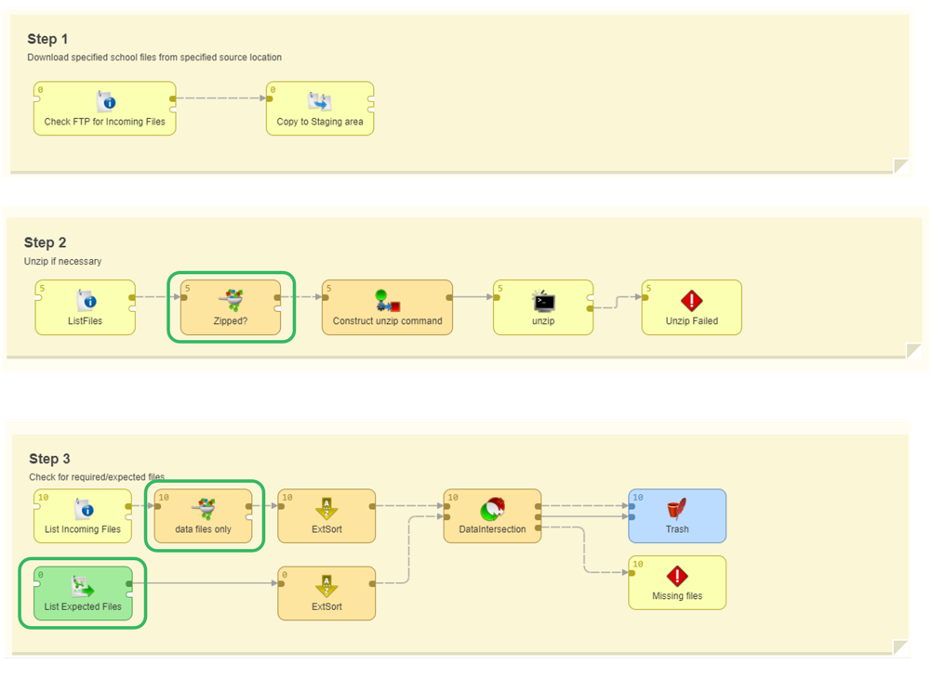
There are several places where we’re doing some kind of check on our data:
- Checking to see if the incoming file is zipped or not (because we want to handle those files differently. We can unzip them if needed, and handle that without logging any errors – adjusting on the fly without manual intervention)
- Checking against a manifest to make sure what we’re receiving is what we’re expecting
- Filtering to make sure we’re only checking the files we want
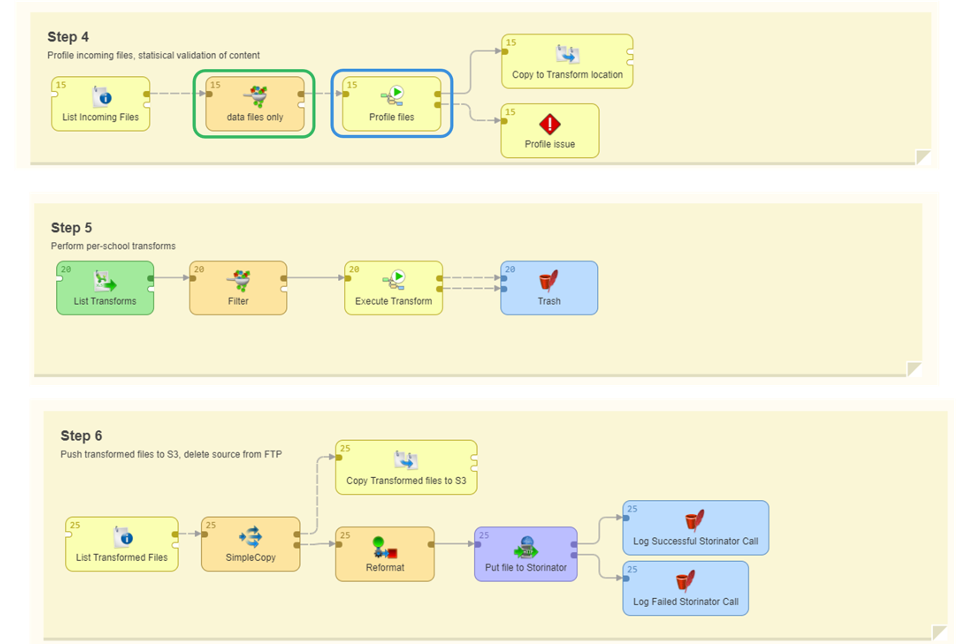
- And the profiling step, which is where the bulk of the additional validation takes place.
And we can drill down further into that profiling step:
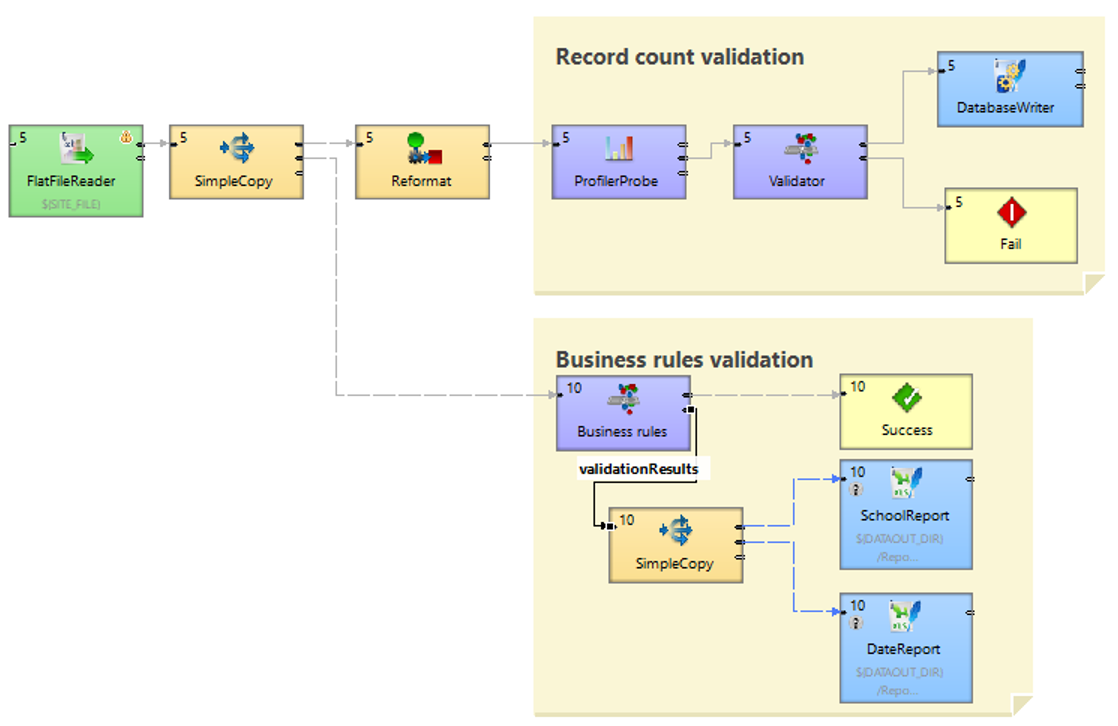
This is our validation step. We’re taking a flat file and running two data pipelines against it: the profiler, to give us that holistic, overarching view; and the business rules validation, where we validate our data against specific rules. We don’t necessarily stop the pipeline if we encounter any suspect data, but we do log it to Excel files.
Watch what this process looks like in CloverDX
Profiling
When we run this process in CloverDX we can see the numbers of files flowing through the process, and how it’s changing at each step. We can also see all the individual records that are coming across, and can see that we’re profiling based on a number of different criteria: for this example where we’re looking at school data we have records based on classes, enrolments, students, teachers and so on.
We can also look at the validation results for each record. For instance, in this example we’re checking for null records. We’ve defined a threshold of 10% - if we’re getting fewer than 10% null records we continue processing, but as soon as it hits that threshold we log an error and alert the user, pulling those results into a spreadsheet.
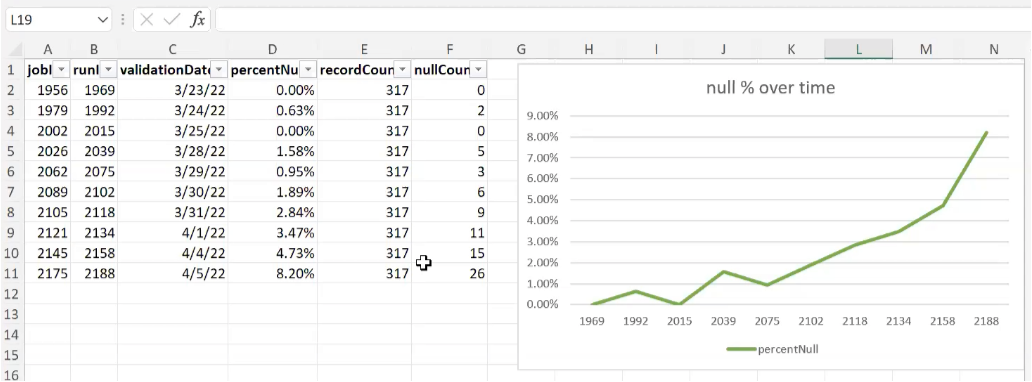
And we can see that even though we haven’t yet reached that critical threshold, the data is trending in the wrong direction – we’re getting more and more null counts. With that information, your end user or support team can address those errors before they even reach critical status – enabling you to fix your data before it even fails.
Business rules validation
Each school in our example has different business rules, different ways they format teacher or class IDs for instance, each very specific to a particular system or data source. The challenge in dealing with data ingestion from multiple sources is how to scale that up, without needing to build new data pipelines for each source?
In this video you can see how, instead of having those validation rules for each source explicitly listed in the pipeline, we’re externalizing the rules.
We’re looking at a file for each school, and depending on which school it is, changing the variables, allowing you to change the data validation rules on the fly per source system.
Error handling
As mentioned above, in CloverDX you can define how you want to handle errors. Some you might want to stop the pipeline for, but some softer errors you might not. But it’s still useful to inform users about those soft errors in a way that’s meaningful and allows them to take action.
In our example we’re creating two Excel sheets, one showing errors by school, and one showing errors by date. You can imagine how for instance you might want to send the by-school report to those schools so they can fix any common errors. The errors-by-date report can be useful internally, for instance to check how your pipelines are running over time.
Data validation with CloverDX
Building data ingestion pipelines with CloverDX gives you complete flexibility in how you manage your data and what data validation rules you want to apply. Building data validation into your automated processes enables you to:
- Adapt on the fly to different data sources, all within a single data pipeline
- Spot errors early, with reporting that allows users to pinpoint and fix problems
- Scale up the number of customers or data sources you can handle, without needing additional technical resource
- Automate the entire end-to-end data ingestion process, right through from detecting incoming files, to data quality checks, processing, loading data to a target and logging every action
Watch the whole video of this demo of data validation in data ingestion processes here. And if you want to talk about how your can build and automate your data ingestion pipelines in CloverDX, just get in touch with us.
Share







