New to CloverDX? Need a refresher on the basics?
Start here for a high level overview of some of the core concepts you’ll find when designing and running your data jobs.
Let’s start with some definitions of terms you’ll come across in CloverDX:
Projects and sandboxes
In CloverDX, a ‘Project’ is a place where you group together multiple jobs or tasks that relate to each other.
Usually, one project corresponds to one use case, but if you’re a large organization maybe you’ll have one project per customer, or per department (such as Finance or Marketing). There’s no limit on the number of projects you can have.
The best guide for creating new projects is if you cannot figure out a name for your project (or only names like “Misc”, “Everything”, etc. come to mind) then you should split it into multiple projects that each cover only one area.
When you create a new project in CloverDX, you’ll see it has a predefined structure. You don’t have to use this structure though. We like to try and help you out by giving you a recommendation on how to start. You can freely change the layout but we recommend you don't stray too far from it to help your fellow data engineers understand the project quickly if they are trying to learn about it.
The CloverDX default project structure with number of directories and files:
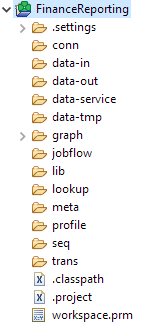
For more on best practices when setting up a project in CloverDX, read the in-depth post over on our Tech Blog: Starting a new CloverDX project.
Local projects
You’ll probably start by creating a local project. It will live just in CloverDX Designer, and you run it on your machine as you’re building it.
Note: Everything in CloverDX is just a readable text file (mostly xml), meaning it’s possible to figure out what a CloverDX job is doing just by looking at the files.
Server projects
When you want to do something more complex or share your work with the team, you’ll typically deploy your project to a CloverDX Server “sandbox”.
One project corresponds to one sandbox on the Server.
Why “sandbox” and not “project”?
At first glance, a sandbox on CloverDX Server is the same as a project in Designer – a directory of xml/text files.
But a Server sandbox adds more than you’ll find in a local project. You’ll get settings attached, e.g. access permissions which configure who has read/write access; runtime settings to configure if it can run in parallel/how many instances; and more.
And similarly to projects in Designer, you can have as many sandboxes as you like on your Server.
What’s inside those projects and sandboxes?
Some more terms you’ll come across quickly when you start using CloverDX:
Jobs
One of the most important terms in CloverDX, a job is simply how you define the steps you want to perform with your data and how your data flows. There are a few types of jobs, but they all use the same concepts, so once you know how to create jobs of one type, you’ll know how to do them all.
Types of jobs
- Graph (grf files): Graphs are the most common type of job and represent data transformations. They do something directly with the data (records) you’re processing. For example:
- Connecting to a database, downloading data, performing validation and producing a report
- Reading a csv file, applying some sort of business logic, and loading into a Snowflake warehouse

- Subgraphs (sgrf): Similar to graphs, but the goal is to allow you to reuse parts of logic in multiple places. A very common use case is for a connector to be created as subgraph. To create such a connector, you start with a graph, then select part of it and tell CloverDX to create a subgraph from the selection. You then have something you can use as many times, in as many places, as you want.
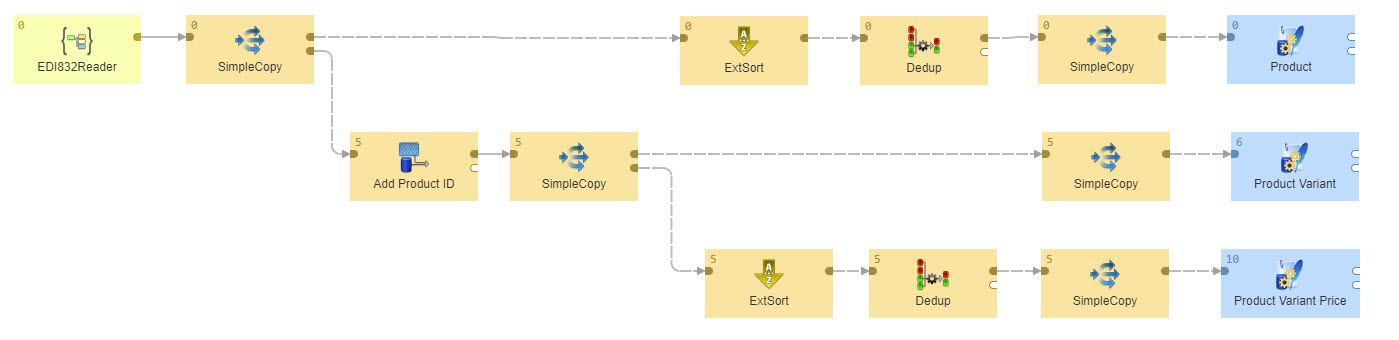
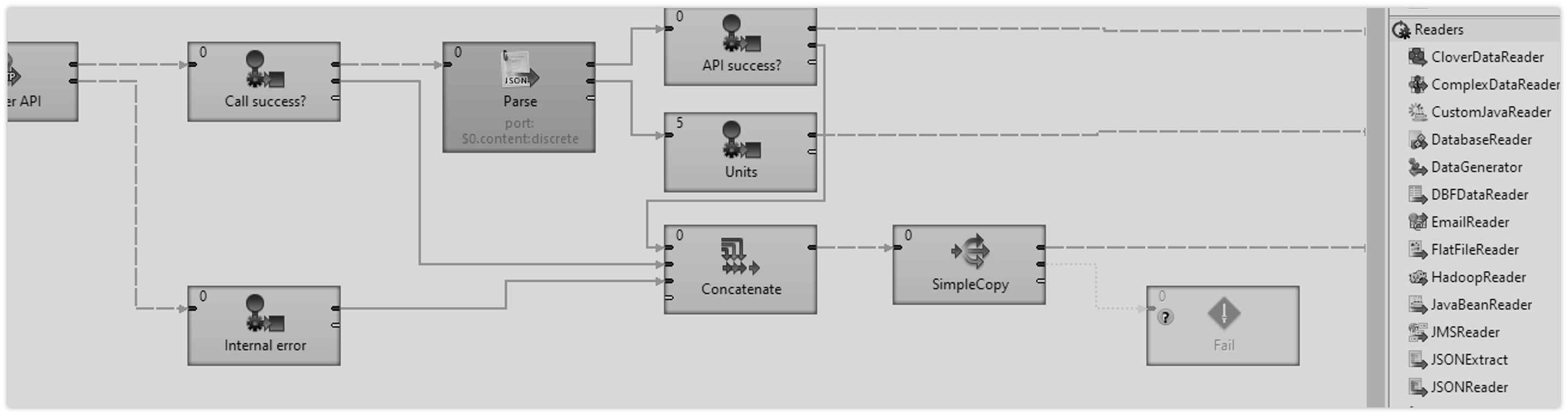
- Jobflows (jbf): A jobflow in CloverDX is essentially an orchestration layer, enabling you to run a number of other jobs (whether graphs, other jobflows, or anything else) automatically. A jobflow allows you to track job dependencies, make sure things execute in the right order, and monitor the execution so you can react if anything fails.
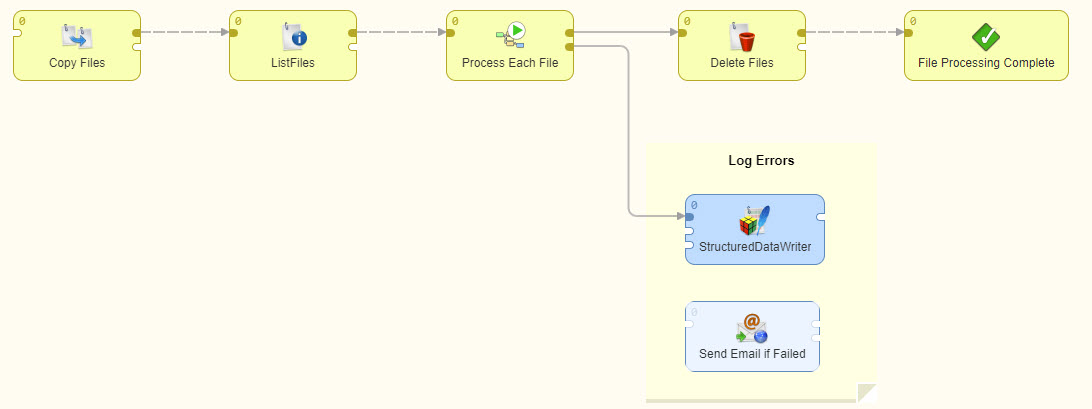
- Data Services (rjob): A Data Service job publishes APIs on CloverDX Server. It enables you to create and manage applications with a user interface on top (what we call a ‘Data App’).
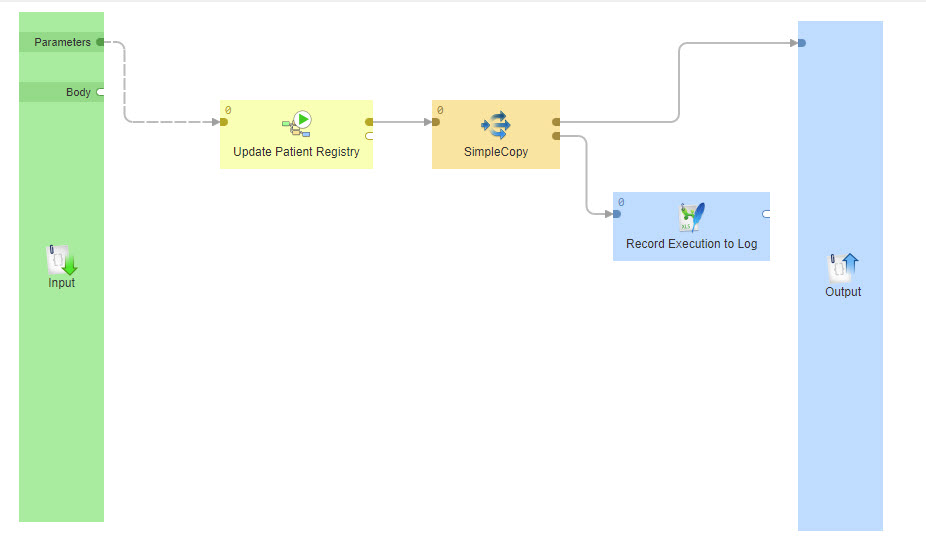
How do you create jobs in CloverDX?
You create jobs in CloverDX Designer – a development environment designed to help you create and manage your data jobs.
In the Designer UI you can see your job in the middle (consisting of components and edges); your project(s) on the left; and your palette of components on the right. At the bottom you have your console to see results when you run something – shown in green when everything’s fine, red when it’s not.

How do you run jobs?
The best way to run jobs is on Server. The CloverDX Server tracks everything you do. If you run thousands of jobs, it’ll remember all of them – you can go back and look at the history of everything that happened. The Job Inspector module then allows you to see what the job itself looks like and how much data was processed. You can do everything you would expect from an environment designed for multiple users in an enterprise (e.g. manage permissions to ensure data security, and more).
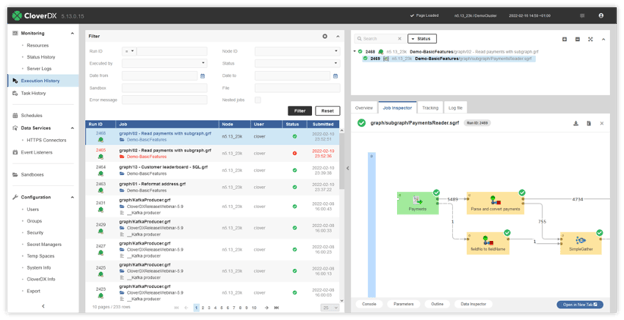
You can run your jobs directly from Designer – even when they are stored on a Server. This allows you to use the powerful Designer interface to investigate and build your job quickly.
How do you work with CloverDX in a team?
Let’s start with a simple example of a project you’re designing and running by yourself.
Project lifecycle: a simple case
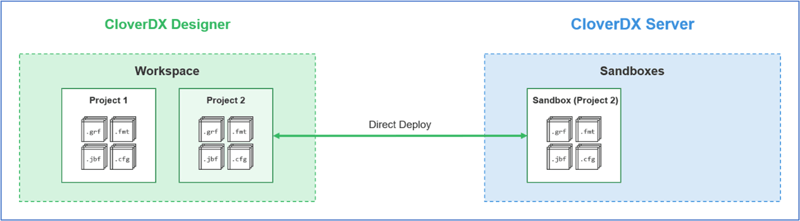
- Create a project in Designer
- When you want to run your project, you publish it to Server. This is done directly from Designer, it’s simply a case of right-clicking on your project, picking the “Convert to Server Project” context menu option and then selecting your Server.
- The project then becomes connected to your Server sandbox. Your local Designer project lives locally, the Server sandbox lives wherever your Server is, but crucially when you make changes in Designer, they’re automatically performed in Server (both projects are synchronized and the sync is two-way – changes made on Server will also show up in your local copy).
- When you hit the run button, your job runs on Server. But the Designer will keep tracking it and will show you the progress.
Project lifecycle: working in a team
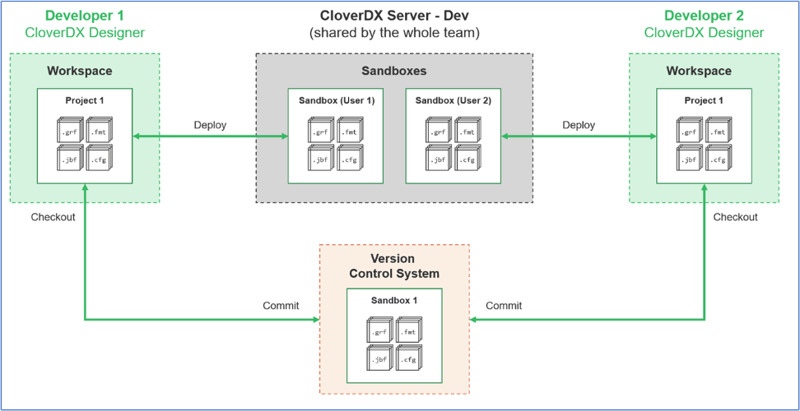
When you’re working in a team in a development environment, the process is basically the same – but typically you’re adding in version control.
- Create your project as before, but publish it to version control* from Designer
- Everyone else connects to the same version control system and pulls the project from there. They can make changes, you can make yours, and version control is where the latest version of everything lives.
- This gives you the safety of having the full history of everything that’s been done
- You can use your existing processes for working with version control – CloverDX will work with any branching strategy you already have.
- When you deploy to Server, the best practice is to have one sandbox per user, so nothing interferes with anything else.
- Note: You can deploy one project multiple times to Server
*CloverDX integrates with all major version control systems. For a closer look at working with version control, watch our webinar: Effective Version Control and Teamwork in CloverDX
Getting to production with DevOps
Taking things one step further, when you’re deploying to production, you’ll typically want to use some kind of DevOps automation in your process.
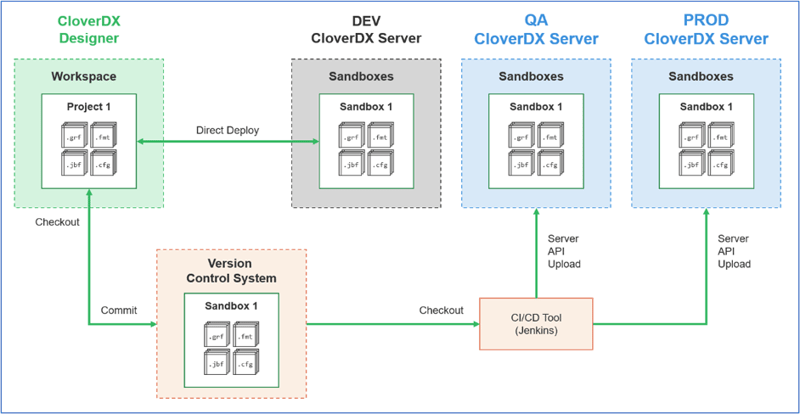
- The initial process is the same as above – you’re still using version control and working in a development environment
- But when you want to promote to production, you’ll do it from version control. Typically, you’ll grab your project from your version control system, deploy to QA, then to production
- You can do this manually, or you can use CI/CD tools such as Jenkins, CircleCI, or others to easily automate everything
- This process is the core of DevOps – create a project; use version control to manage it; and use automation to deploy and test
A more in-depth look at CloverDX project lifecycles
If you want more detail on any of this, the post Understanding the CloverDX Project Lifecycle over on our Tech Blog goes more in-depth on everything, including some best practices for deployment, development and team collaboration.
Share






