
When it comes to your data migration process, conducting a ‘small’ move to the cloud isn’t always as easy as it sounds. When factoring in cost, maintenance and skills required, you may end up orchestrating an integration that’s far too difficult to sustain.
We faced a similar issue at CloverDX. What appeared to be a simple solution on paper transformed into a fascinating trial and error exercise (with a successful ending!).
Here’s our cloud migration journey, from start to finish, including our observations, predictions and tips.
You can watch the webinar where we walk through this use case here: Moving 'Something Simple' To The Cloud - What It Really Takes
The idea behind our data migration process
Our idea was simple: create a basic financial reporting integration using data housed in our HubSpot account. The report tracks various events in HubSpot - such as the creation of an invoice or whether we’ve closed a new deal - and notifies the financial teams through an email.
However, HubSpot couldn’t create the reports we needed. So, we had to use other tools.

Version one: On-premise only
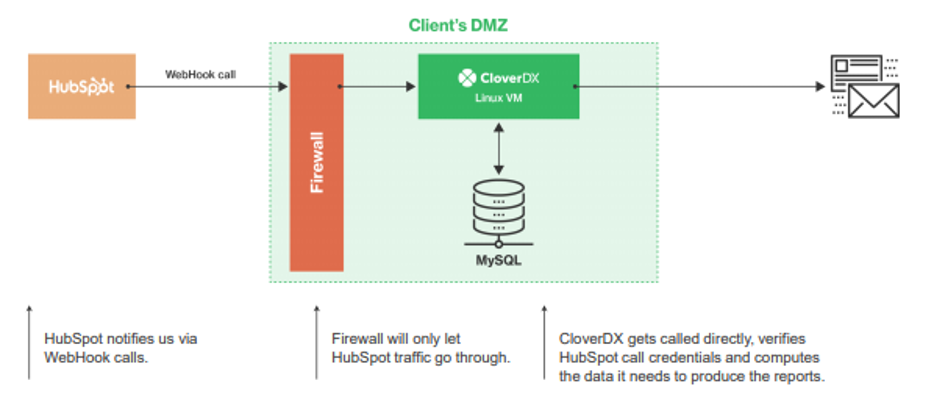
Initially, we opted to create the application on-premise.
In the following illustration, you’ll see that CloverDX is the main conductor of this integration. Through HubSpot’s “webhooks”, CloverDX is called directly whenever a new event notification occurs.
From here, CloverDX computes all the data necessary, packages it up and sends it out to the relevant team members.
How did we do it?
Version one’s tactic was to:
- Deploy CloverDX in a virtual machine that’s hosted on-premise
- Use a MySQL database to track the processed data
- Hide the integration behind a firewall to restrict sensitive data from danger
Resources required (we’ll talk about why this is important later on…)
- A developer to build the integration
- IT admin to provision the network, virtual machine, emails and other tasks
- Support team to manage the application
- Developer to maintain the integration and implement any changes
Overall, the integration would have been easy to build. Since everything used was pretty standard, we had the skills and hardware required.
However, it turns out maintaining this solution would be time consuming as we would own and manage every single layer of the solution – from hardware, operating system, security to the CloverDX application itself. That’s a lot that can go wrong, especially if you don’t have a large IT team operating 24/7.
For your business, the case might be the same.
The on-premise cost predictions
- The hardware (virtual machine) is likely to be very cheap
- However, we had no prediction of what the maintenance costs might be
Some further observations
Using this ‘old school’ architecture would mean:
- Continuous patching on all software
- Risk of downtime, should the network or power cut out
- Potential loss of HubSpot notifications during downtime instances
- Regular updates to ensure security is watertight and to prevent hackers
Our rating?
2/10. It would be pretty painful to manage, to say the least.
Version two: Onwards into the cloud
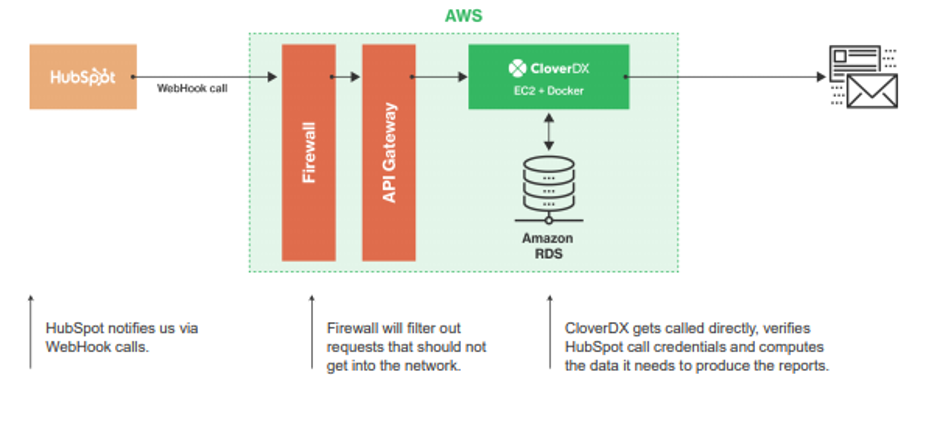
This is where the cloud strategy came into play. In cloud, you’re free to pick from “bare metal” to fully managed serverless option like the AWS lambda, APIs, etc.
In this version, the fundamentals of the integration remained the same, only this time we ran it in the cloud rather than our own network. We kept a firewall and enabled an API gateway to filter out any unnecessary requests. HubSpot simply calls CloverDX, which then computes the data needed to produce the reports.
Resources required
Overall, the skills needed in version two stayed largely the same as version one. The only (small) difference being that Amazon would take care of the database security and maintenance, and potentially would help us with the VM as well.
The cloud cost predictions
There were some slight differences to the cost outlook.
- With version two, you would pay for the cloud instances rather than your own internal instances. This is easier to predict, but for any business conducting a cloud migration, it’s important not to over-service and spend more money on wasted cloud space.
- There’s still an unknown cost prediction for maintenance. However, this time you’d have to maintain a cloud environment, rather than an on-premise environment.
Further observations
- You would still have to patch the OS continuously (but in the cloud, in this instance)
- If you experienced downtime, the HubSpot notifications would still be lost completely. What’s worse, even without you knowing.
- That said, the security of the integration improved. If a hacker were to compromise this application, they would only be able to breach a small virtual network, rather than the entire internal network.
Our rating?
3/10. Version two was better, but only by a small percentage.
CloverDX on AWSVersion three: Stepping into serverless computing
Finally, we come to our third version that turned out to be final: serverless.
That’s when we had to radically rethink the architecture. From a simple “naïve” solution in versions one & two we had to fully embrace the building blocks of the native cloud serverless world. For your typical sysadmin that meant learning completely new things.
Although we still kept the firewall and API gateway for security purposes, we completely changed the way HubSpot consumed and sent notifications.
Instead of HubSpot directly calling the CloverDX API, we used the AWS Lambda function to validate the HubSpot API call. You don’t want to allow just anyone to use your API endpoint and you also don’t want to spend too much processing time (read, money) on doing so. The HubSpot API call would then be submitted to a waiting queue (SQS). From here, CloverDX actively pulls data from the queue on a minute schedule and then sends out the necessary reports.
The use of an intermediate SQS queue allowed us to react to differing spikes in data volume, as well as prevent any lost messages, should CloverDX become unavailable.
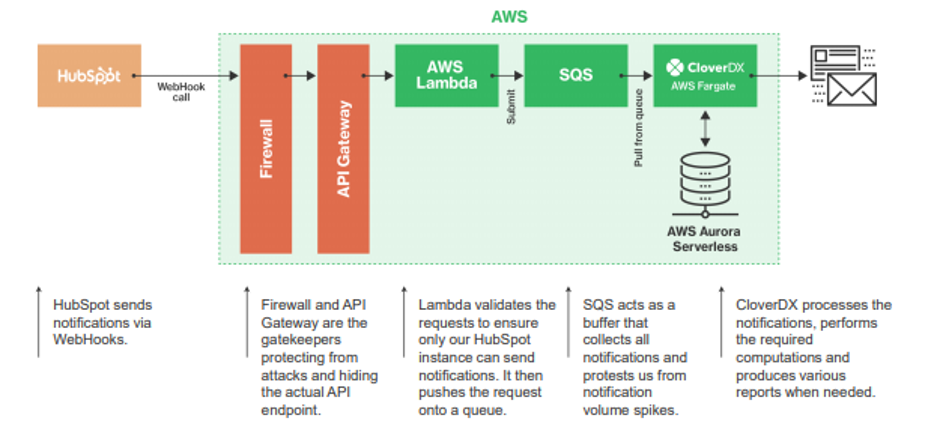
To make the integration easier to manage, we installed the CloverDX into an AWS Fargate instance. As you’ll see from the diagram, everything is run as a serverless service.
Resources required
For the final time, here are the requirements necessary for version three:
- A developer to build the integration – this requires more work than the first two integrations, but it should be easier to run if you configure it properly
- IT admin with the appropriate (experienced) skills to provision the cloud resources
- Support teams will still have to manage the application to make sure CloverDX is running okay and the code is working
- However, the environments will effectively manage themselves as they’re Amazon’s responsibility
- That said, developers will still need to implement any further changes to the integration
The serverless cost predictions
- The perpetual cost of cloud instances make cost predictions much easier to estimate
- Once again, the cost of maintenance is not easy to predict, but Amazon’s software will update itself, leaving you only needing to update expired certificates, monitor logs etc.
Further observations
Our version three, in comparison to our previous cloud migration efforts, features an entirely new programming pattern for increased robustness and scalability.
Here are some final thoughts on the integration:
- The operating system, containers and all other Amazon services are automatically updated – you only need to keep CloverDX and the code up to date
- The messaging queue prevents data loss when the service is down and can handle unforeseen spikes in data
- The integration can scale up easily – if your volume of data is too large, you can simply run another instance of CloverDX
- It’s much more secure– an attacker would have difficulty compromising the multiple services to access your sensitive data
That said, this integration may lock you into an Amazon-only ecosystem. Which could make migrating the application into another cloud provider’s environment pretty difficult.
Our rating?
7/10. Overall, version three provided us with the streamlined and scalable reporting tool we needed. The only downside, of course, being the complexity of setting up the integration and some ongoing support requirements.
Dear cloud migrators: Our advice to you
We hope you’ve enjoyed reading through our data migration ‘trial and error’ process.
As you can see, we initially prioritised simplicity over practicality. As much as an on-premise (or cloud) integration would be easier to build, it would most likely put extra strain on our IT and support teams. Thankfully, our experts created a solution that satisfied the whole team and fulfilled our financial reporting vision.
Before we let you get on with your day, here are some tips for those of you eager to migrate to the cloud:
- Migrating to cloud is not making a one-to-one replica of what you have on-premise. You can start like that, but you’ll quickly end up using the cloud native “elastic” blocks. Don’t waste time then and rethink your infrastructure from ground up if you’ve made your decision to go to cloud already.
- Not every use case is fit for the cloud – some are more transferable than others
- If you wish to perform a cloud migration, ensure your team is equipped with the different set of skills set required
- If you choose to migrate from on-premise, you may end up with some overlapping payments – both for your on-premise environment and your new cloud ecosystem
- Although a serverless integration offers you greater agility, it’s far more complex to build
If you’re interested in know more about how to move a data-intensive process into the cloud, please don’t hesitate to get in touch.

Share







