
Ensuring data quality throughout your data pipelines can be challenging. In this blog post, we explore how to build data pipelines with bad data in mind, and how to build strategies to maintain data quality.
By understanding the sources of bad data, implementing validation and profiling techniques, considering data quality at each pipeline step, and managing data errors effectively, you can mitigate the risks associated with poor data quality.
Understanding data quality
Data quality refers to the assessment of data to ensure its suitability for the intended purpose. Poor data quality, characterized by issues like accuracy, completeness, and consistency, can adversely affect the trustworthiness of the data your users are receiving, and result in bad business decisions.
It's crucial to prevent bad data from entering systems and propagating further, as repairing the damage caused by poor data can be costly and even harm the reputation of your whole organization.
Sources of bad data
Bad data can originate from a number of sources, including human errors during data entry, or software-related issues. For example, point-of-origin errors commonly occur when data is entered or recorded by individuals, leading to inaccuracies. Additionally, software-related factors such as data structure inconsistencies or format mismatches can contribute to bad data.
It's important to recognize these sources and be aware of how easily poor data can infiltrate systems.
Examples of bad data
To illustrate how easily poor data can enter systems, let's consider a few examples.
- Date formats are a classic source of error, with discrepancies in formats causing confusion and misinterpretation.
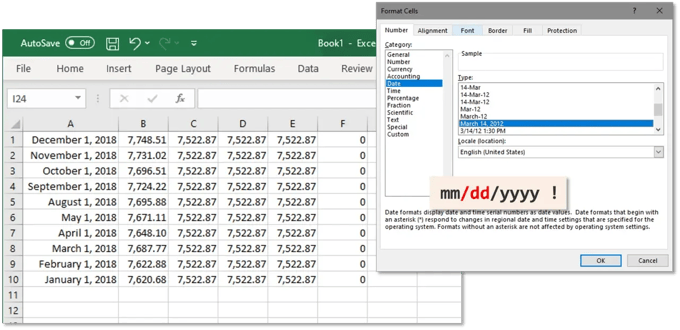
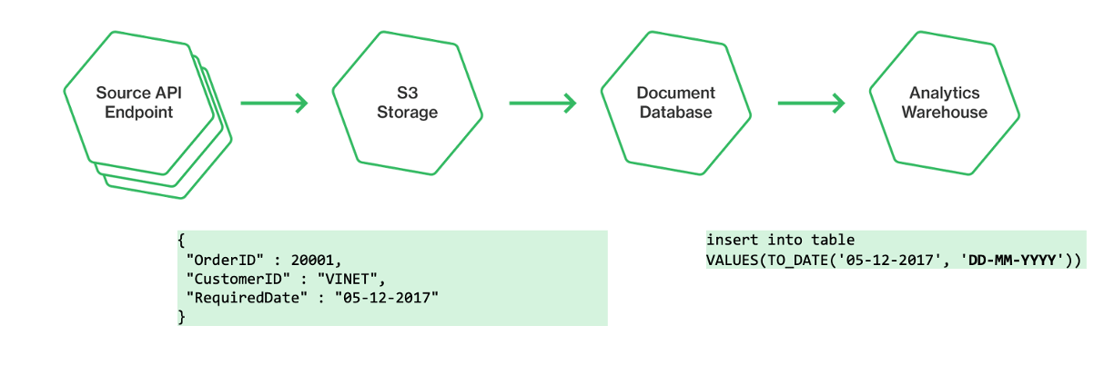
- User interfaces can also contribute to poor data quality, particularly when interfaces evolve while underlying data structures remain unchanged - for instance, a free text field being changed to a multiple choice dropdown - we end up with both types in our database and data users might not be aware of this variation, so aren't designing for it.
- Programmers themselves can inadvertently introduce data errors through simple mistakes like transposing data or inserting incorrect values.
- Finally, case sensitivity can lead to duplicate files and data inconsistencies if not managed properly.
Mitigating bad data risks in data pipelines
Most quality issues arise when you put your data in motion – an integration, data ingestion, or reshaping for use in a warehouse and so on. These data processes typically involve a data pipeline with multiple stages, each of which can allow errors to creep in. And they snowball – a seemingly small error can cause further errors throughout the pipeline and result in improper results for the end user.
Here's three things (plus one bonus thing) you can do to in your data pipelines to ensure better data quality:
1. Validation and profiling:
Incorporate explicit data quality checks in your pipeline, such as validation and profiling stages.
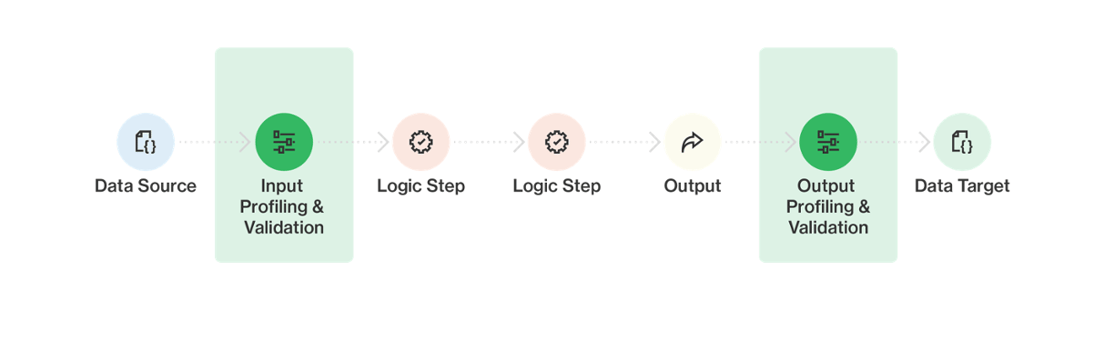
When building your data pipeline, you should build in stages that explicitly deal with data quality - scrutinizing the data on the way in and the way out. Two key ways of doing this are data validation and data profiling:
- Validation involves applying business rules to each record to ensure data meets specific criteria (such as: Does the ID field have right number of characters? Are the begin and end time stamps in the right order? Do I have a valid phone number in one of these 3 fields?) Records that pass the validation checks can proceed to the next step in the pipeline; those that don’t get pulled out for assessment and correction.
- Profiling involves creating statistical profiles of entire datasets to identify questionable data. These checks can be added at various pipeline stages, helping identify and filter out bad data effectively, and detecting when data quality might be beginning to decay.
2. Data quality in each pipeline step:
Recognize that poor data quality can emerge from any stage in the data pipeline.
Implement checks at each step to capture and address data quality issues as soon as possible, reducing the chances of propagating errors further downstream. Similar to unit testing in software development, treating each pipeline step as a testable component ensures early detection and resolution of data quality problems.
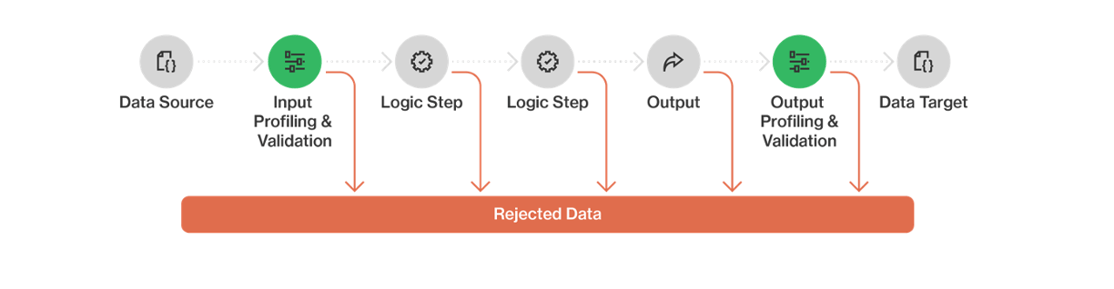
3. Data error management
Instead of merely capturing data errors, consider establishing a data error management process.
This process acts as a central hub for collecting rejected data from the pipeline, allowing for effective correction and reprocessing. It involves a combination of people, processes, and technology, and the data error manager should use a standard format for reporting errors.
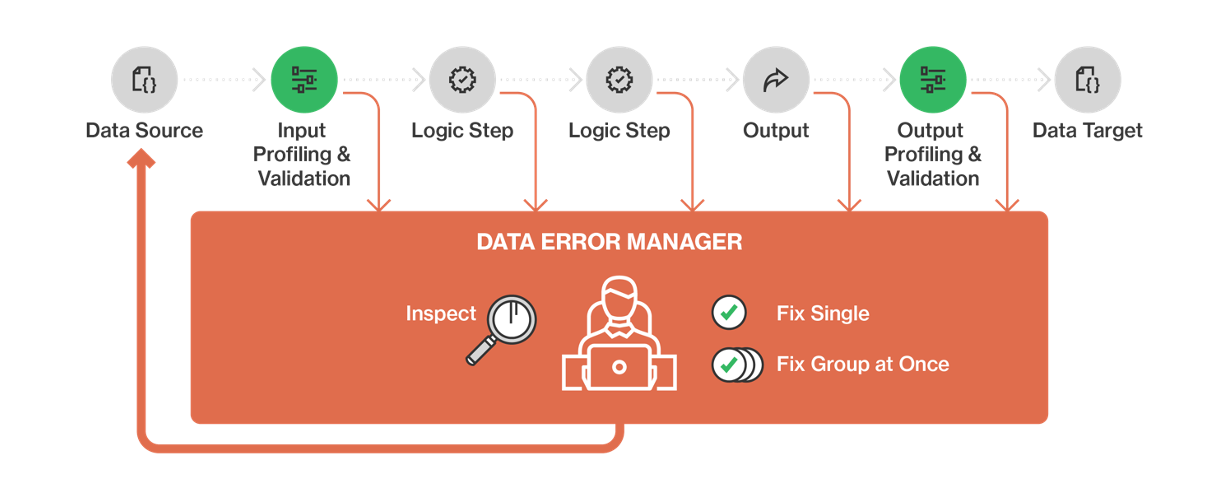
One important consideration is who has responsibility for fixing data errors. Even though IT staff might be the first to detect errors in the pipeline, they’re probably not the right people to correct it – they might not know the context of the data, or have the authority to fix it. Involving business users or domain experts ensures proper context and authority for making data corrections.
It's also important to standardize error reporting formats to streamline the resolution process. Error reports need to be presented in a way that a human can understand, and that gives them an actionable piece of intelligence they can act on to correct the data.
4. Data about your data
Implementing these stages into your pipelines to identify and handle bad data can not only improve your immediate data quality, but it can also give you a valuable opportunity to identify larger business issues such as flawed processes or training requirements (e.g. 'All of our West region POS devices are using the wrong timestamp') or uncover and reconcile differences in interpretations or definitions (e.g. 'Is the project closed because the Status field says Closed, or because the Close Date is in the past?).
Good responses to bad data
Building data pipelines with bad data in mind and maintaining data quality is essential for organizations to derive meaningful insights and make informed decisions.
By understanding the sources of bad data, implementing validation and profiling techniques, considering data quality at each pipeline step, and effectively managing data errors, organizations can mitigate the risks associated with poor data quality.
Having a standardized error handling process built into your pipelines can also give you valuable information about your business practices, enabling you to fix even more data quality issues at source.
Investing in robust data quality practices ensures that data remains trustworthy, reliable, and fit for its intended purpose throughout the pipeline.
Download a free trial of CloverDX and start building your own error handling rules.
This post is based on a webinar of the same title. You can watch the full video, presented by CloverDX Solutions Architect Kevin Scott, below:
Share







