
Manage data in Snowflake with CloverDX
Faster, easier data loading and management.
Powerful data management
ETL for Snowflake
Snowflake is a cloud-based data storage and analytics engine – or a “data warehouse as a service”. It allows you to store massive amounts of data in your warehouse and make it accessible to all your users while providing maximum query performance.
CloverDX acts as an ETL tool for Snowflake, enabling you to easily connect to your Snowflake data warehouse, load or unload data and run various queries to manage your data.
CloverDX is a Snowflake Partner


Connect
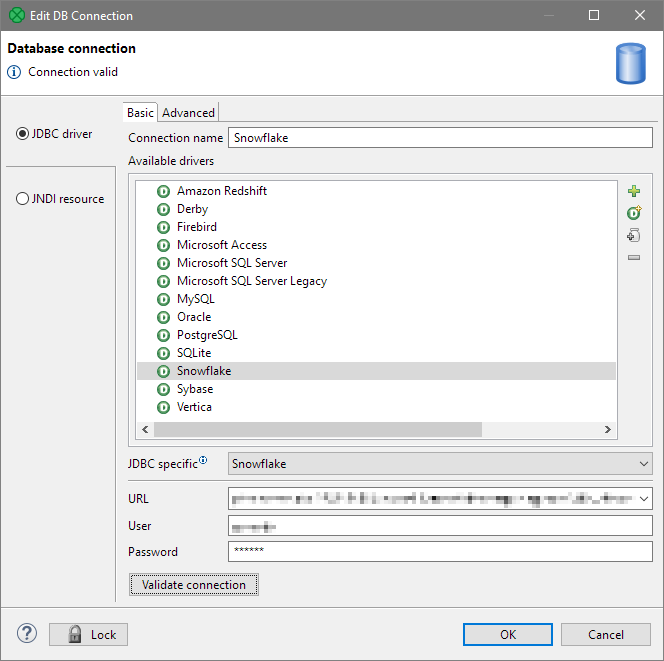
Connecting to Snowflake
CloverDX offers native connectivity to Snowflake using Snowflake’s JDBC driver. The driver is bundled with CloverDX starting with CloverDX 5.10 (released in March 2021).
CloverDX provides Snowflake connectivity out of the box - you don't need any additional software or set-up. Simply configure your connection and start working with your data.
Once you create your Snowflake connection, you can manage your data using built-in components in your CloverDX graphs.
Manage
Working with data in Snowflake
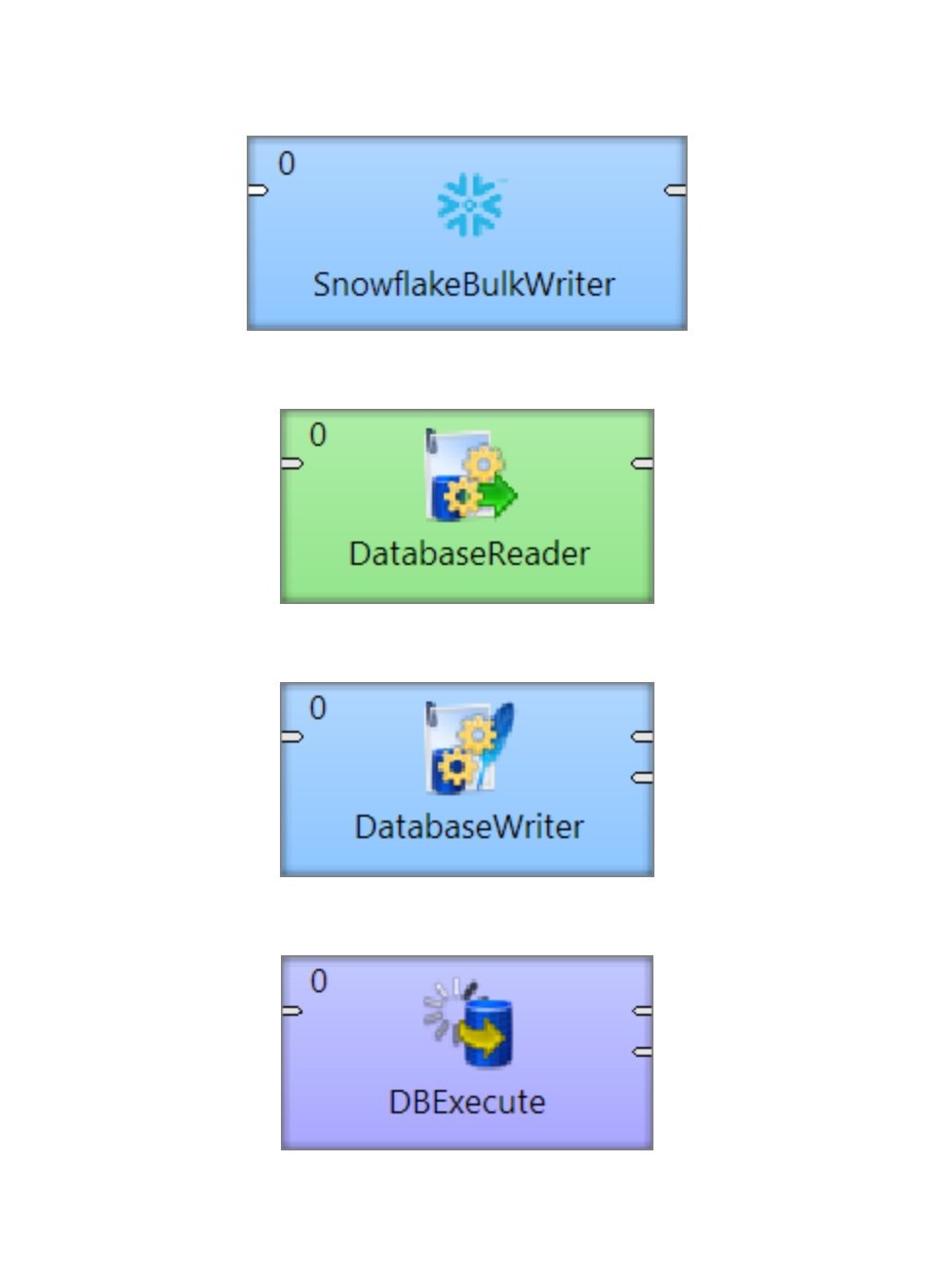
CloverDX offers built-in components that can help you load and manage your data in Snowflake :
- Quickly bulk load large data volumes of data using the SnowflakeBulkWriter. This component is most useful when inserting huge data volumes since it's many times faster than running queries one by one.
- Read data from Snowflake by running any SELECT query using the DatabaseReader component. This component allows you to run complex queries (including joins) and fully supports Snowflake SQL dialect.
- Write, update, or delete data in your Snowflake instance by using the DatabaseWriter component. This component allows you to run queries that insert , update, delete or modify data in your Snowflake.
- Run DDL queries (like creating new users, warehouse, etc.) using the DBExecute component.
Together with the jobflow orchestration layer you can use CloverDX to build and manage complex warehouses in your Snowflake and work with any data sources you need.
Load
High-performance Snowflake data loads
As an ETL tool for Snowflake, CloverDX offers fast loading of data.
The CloverDX SnowflakeBulkWriter component performs all operations that are required to load large data volumes into Snowflake.
It will process your data, submit it into the Snowflake staging area and then load into your designated table.
You can even create a target table automatically based on the data structure that is flowing into the component for even more generic data flows.
This is the fastest way of getting your data to Snowflake, as the data is uploaded to the cloud in parallel in multiple threads. This means Snowflake can run its data loads in parallel as well. As such, this is the best way to load large volumes of data into your warehouse.
Requirements
- CloverDX 5.10 or higher
- Snowflake account

On-demand webinar
Loading data into a cloud data warehouse
See how you can use CloverDX to automate data feeds into a Snowflake or Redshift data warehouse.

Watch now
Loading data into a cloud data warehouse.