Data anonymization
Share data safely with anonymization rules
Centralize and share anonymization policies, and apply them quickly and easily to all levels of your data.

Anonymization at every level
Make data easier to share
Whether for development or testing purposes, or simply needing to share data with a third party, it can be time-consuming and risky to anonymize data to make it possible to share.
With CloverDX you can quickly and easily apply basic anonymizations at different levels of your data:
- Non-technical users can instantly anonymize specific columns in CloverDX Wrangler
- Data engineers can configure shared anonymization rules that can be easily dropped into data pipelines
- Data owners can define anonymization policies in Excel that can be applied automatically
- Create an anonymized copy of an entire database at the click of a button
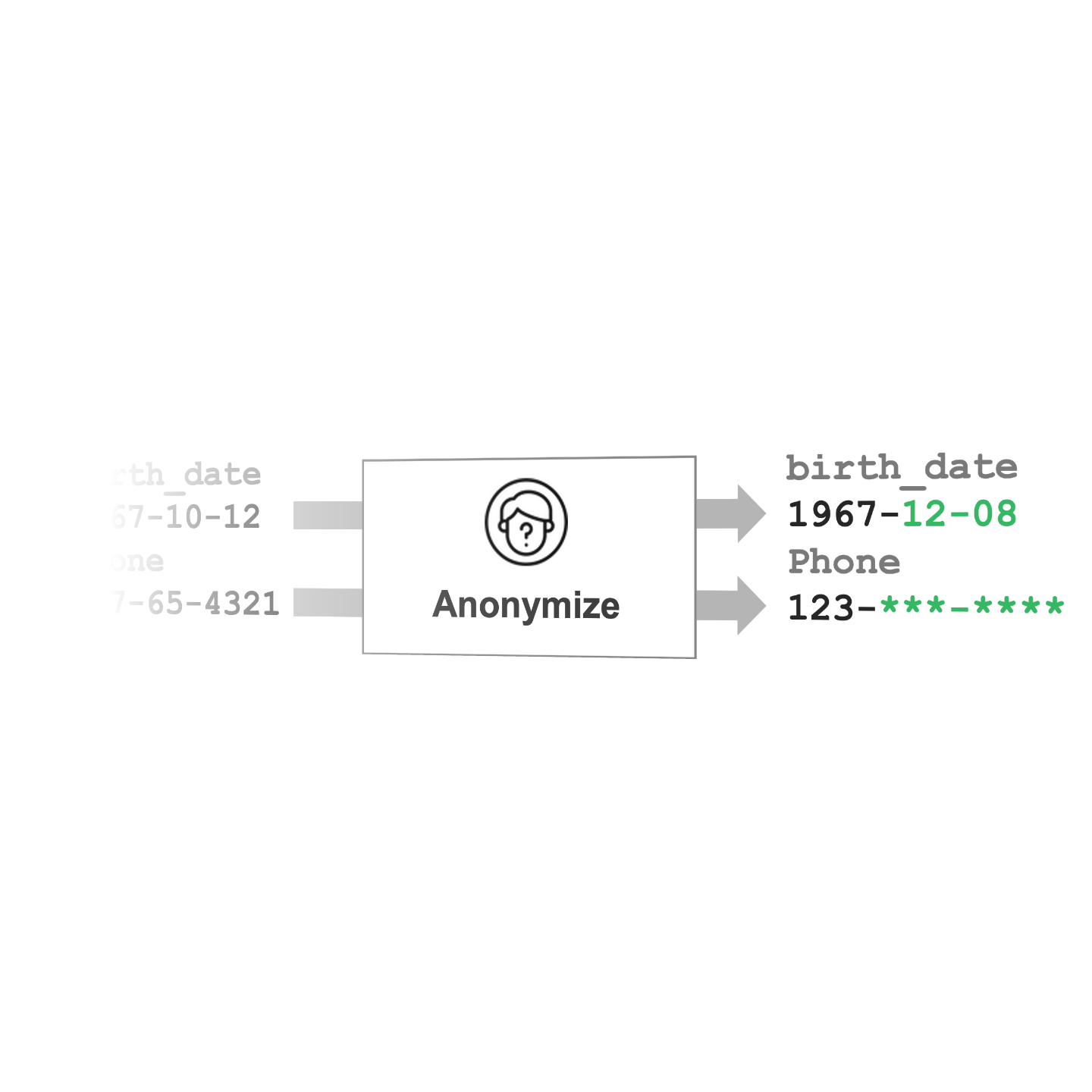
Anonymize columns
Quickly anonymize sensitive data
Apply field-level anonymization at the click of a button with CloverDX's Wrangler's built in mask, randomize and noise functions.
Add steps to Wranger recipes to anonymize columns by:
- Adding noise to a date: Creates a new random date within a specified range
- Add noise to number: Generates a new random value within a specified distance from the original
- Mask text: Mask parts of private data such as names, phone numbers or credit card details
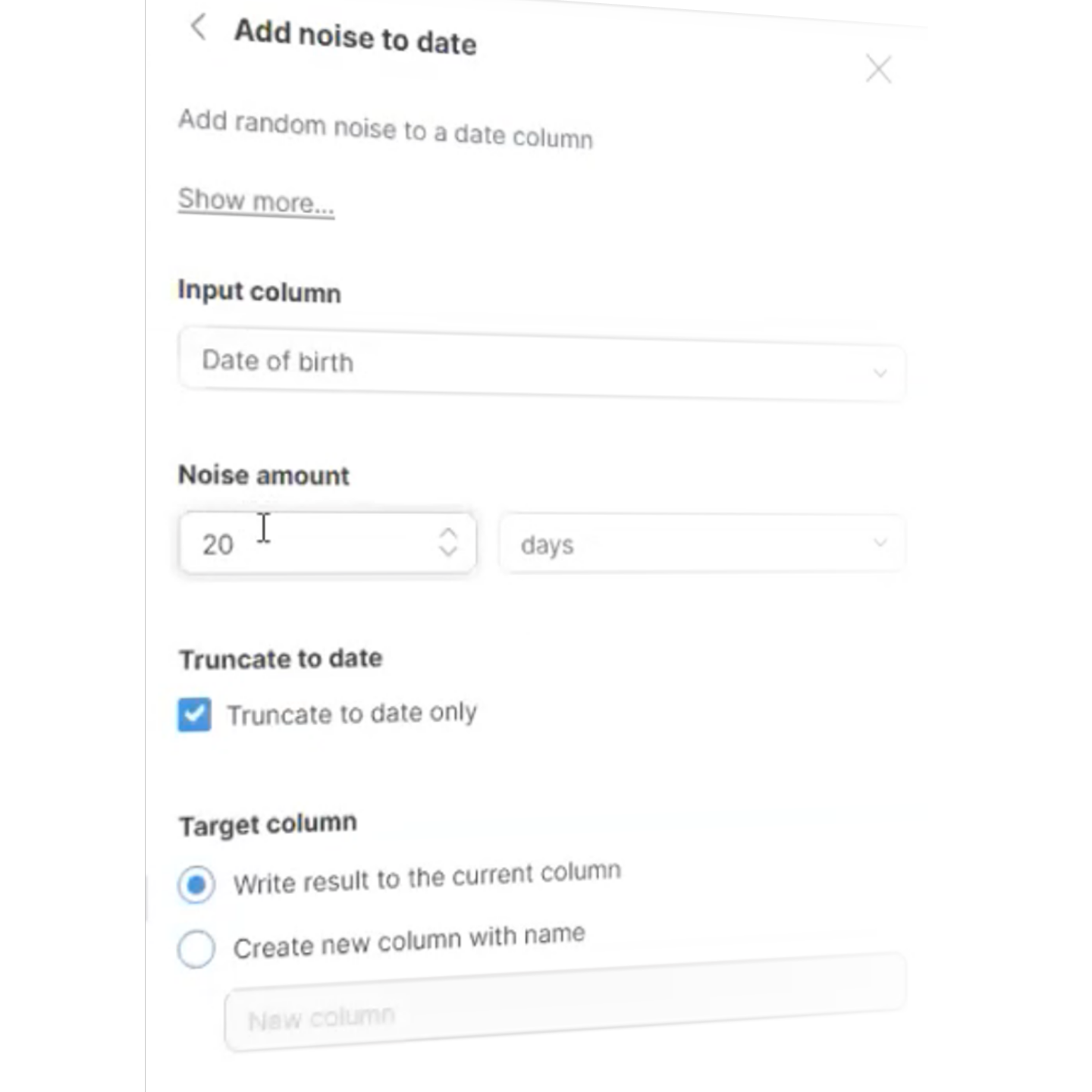
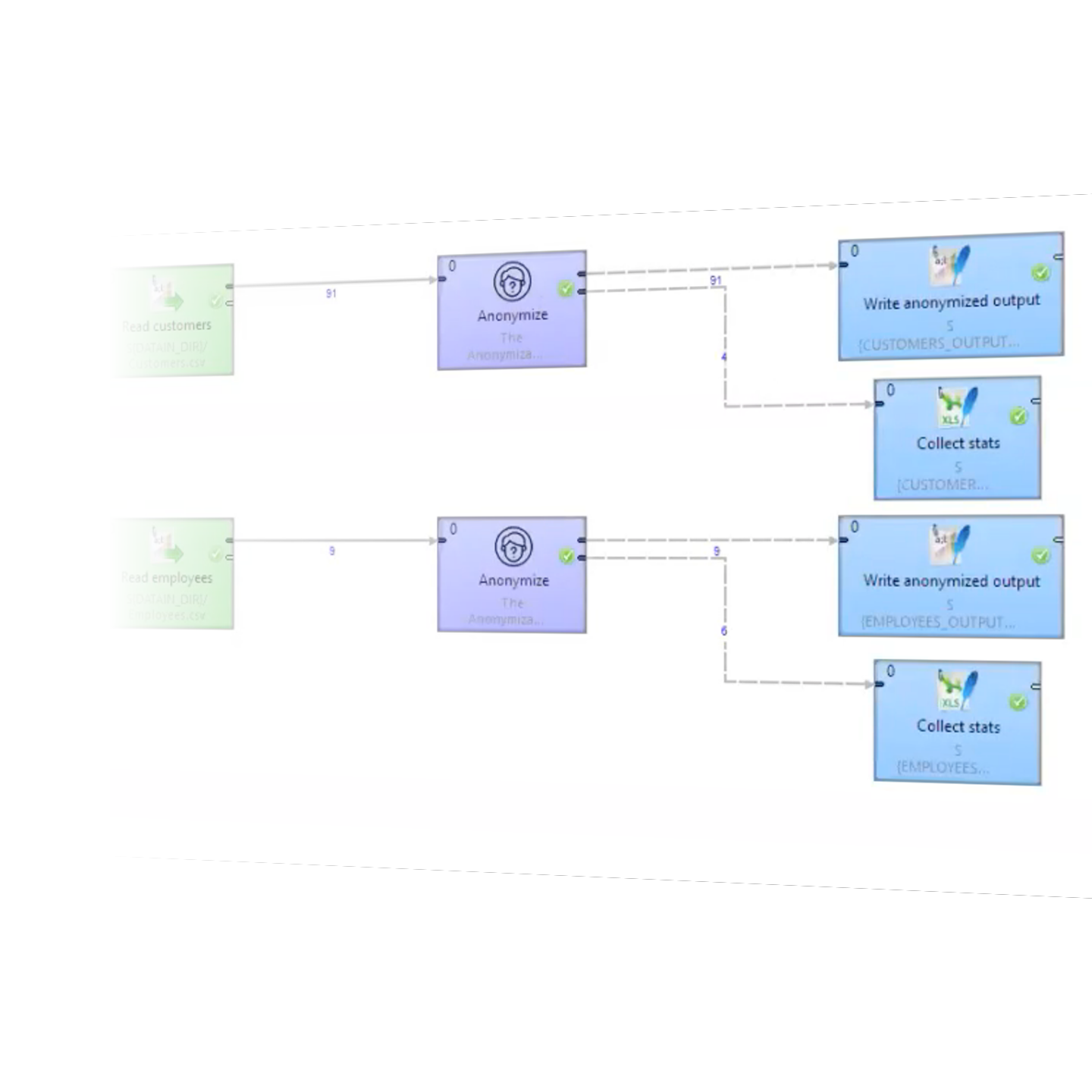
Centralize anonymization policies
Eliminate human error when it comes to applying anonymization rules.
Centralize management of anonymization policies and make anonymization easier to apply.
Define your organizations anonymization policy (or policies), and make it available as a CloverDX component. Users can just drop the ‘Anonymize’ component into their data pipelines to ensure all data is subject to the same rules, and the resulting output is safe to share.
Easier compliance, with no extra effort.
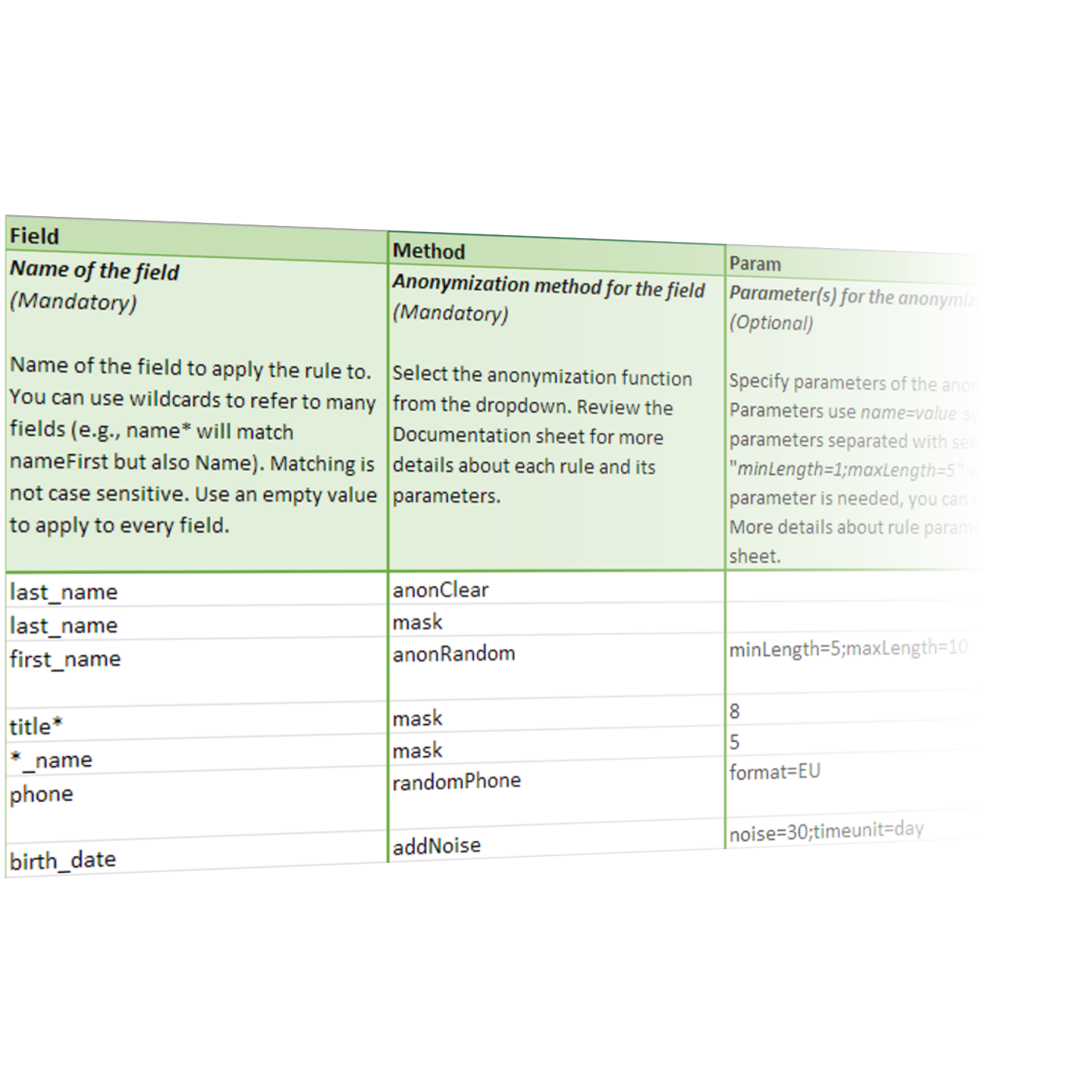
Empower data owners
Enable data owners to define anonymization rules, without needing to code
Your organization’s anonymization policies can be defined by non-technical data owners in Excel. CloverDX takes care of converting Excel definitions into executable rules that developers can apply just by dropping a component into a data pipeline.
Data owners get control over keeping their data safe, and can alleviate responsibility from developers.
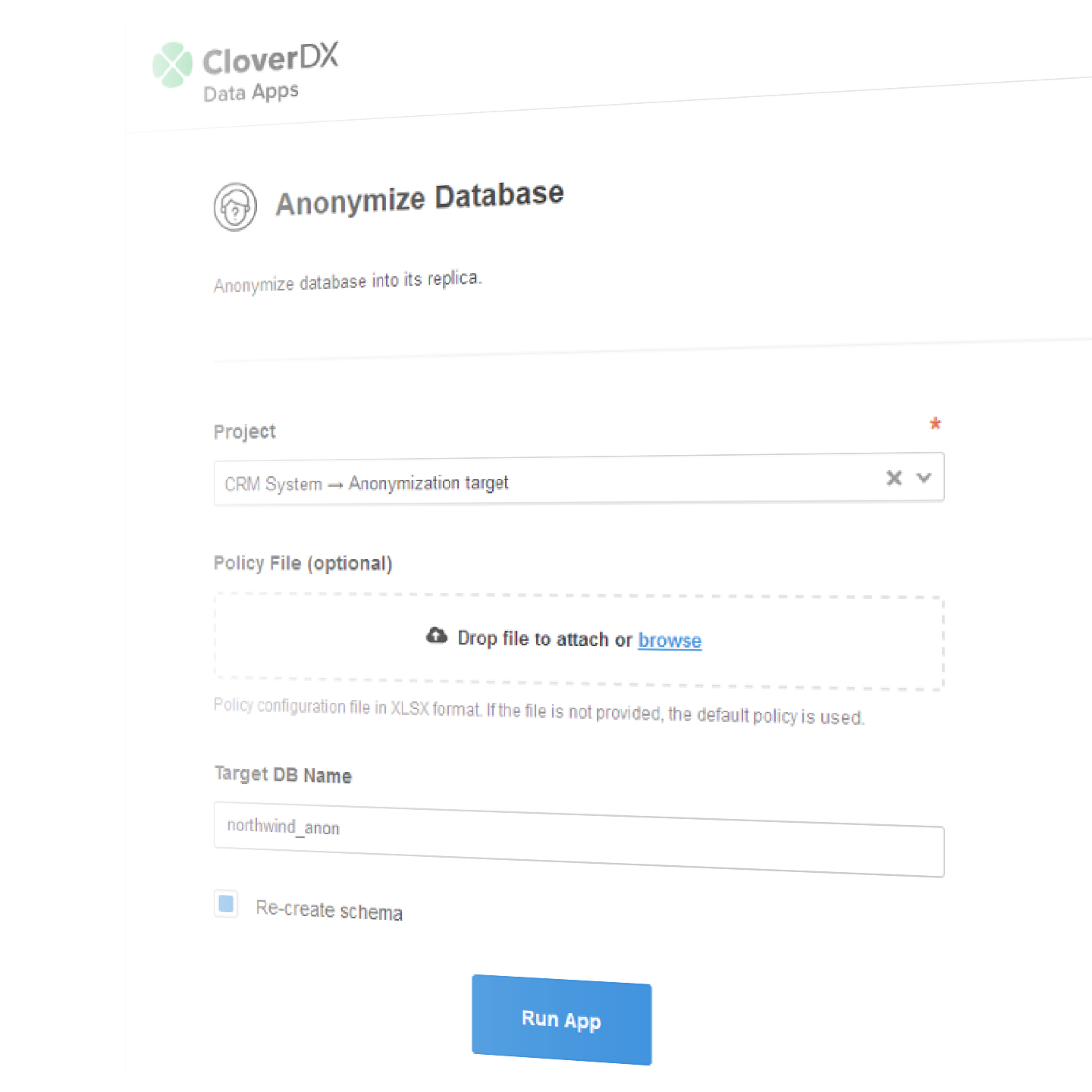
Anonymize databases
Single click anonymization of an entire database
CloverDX has a pre-built solution for anonymization of SQL databases at the click of a button.
Point it to a database and an anonymization policy, and it will create an anonymized copy of the database, making it safe to share for testing or analytics.


Column level
Built in rules in Wrangler to easily anonymize fields. Add random noise to a date column or a number, or mask values in string columns.

Record level
Data engineers can configure and share anonymization rules by wrapping Anonymization rules into a component in CloverDX Designer. Data sets can be anonymized simply by passing them through the component.

Database level
Apply an anonymization policy to an entire database with one click, making it simple to share data safely with third parties.