
Data integration and data ingestion may sound similar, but they have one key difference. And it all comes down to the number of systems you're working with.
When you're working with combining data from multiple systems, it's data integration. But if you're just getting your data from X to Y, it's data ingestion.
Of course, we're only skimming the surface of what you need to know here.
So, let's look deeper into the two processes and how businesses manage them.
Watch the full video on Data Ingestion vs Data Integration: What's the Difference? here.
What do we find when we ask the internet for definitions of data ingestion and data integration?
Data integration
.png?width=1321&name=Screenshot%20(336).png)
'Data integration involves combining data residing in different sources and providing users with a unified view of them.'
- [Wikipedia]
This definition is very accurate.
Data integration is often more complex than data ingestion, and consists of combining data. Usually you don't end up with two different data sets being pushed into a target, but rather a single data set that's augmented from multiple sources. These could be applications, APIs or files.
Again, the key difference here is that integration involves combining multiple sources together.
Data ingestion
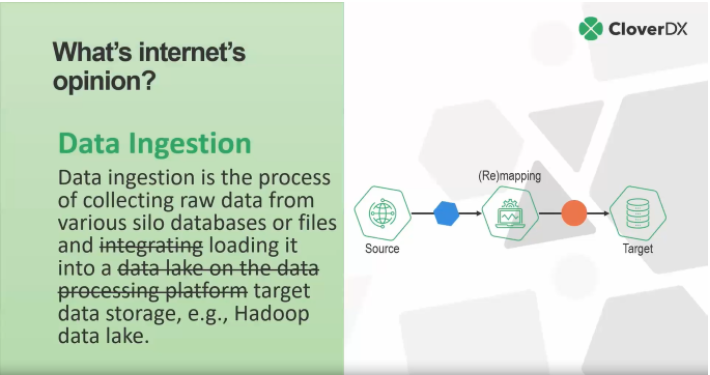
'Data ingestion is the process of collecting raw data from various silo databases or files and integrating it into a data lake on the data processing platform, e.g., Hadoop data lake'
Unfortunately, this Googled definition isn't quite as accurate as the first.
Firstly, the definition references 'integrating', which is (as we've explained) a different process. But beyond this, the definition is also very specific. You can collect data from any system, not just siloed databases or files.
If we were to reword this definition, we would instead state that:
'Data ingestion is the process of collecting raw data and loading it into a target data storage, e.g., Hadoop data lake.'
That said, it's important to note that the target doesn't have to be a lake. It could be anything.
For instance, it could be an e-commerce system such as Shopify. Essentially, data ingestion involves taking data from a source, remapping it to the target and ensuring the source and target can 'talk' to each other, and then loading it to the target.
Data ingestion tools - key features you should look forExploring how businesses manage these processes
Let's now dissect how organizations typically tackle data integration and data ingestion respectively.
Early-stage data integration
As data integration is complex, many businesses use high-level programming languages, such as Python, PHP, and Perl as a starting point.
These languages are great as they have libraries and database connectors that make them easier to work with.
Businesses may also choose to embed cloud SDKs (software development kits) into their integration processes. These kits work easily alongside programming languages and cloud services, such as AWS S3 or Azure file storage.
However, while many businesses are apt at data integration, eventually cracks begin to appear.
Usually, this is a result of missing or outdated documentation. For instance, Person A built an integration years ago and then proceeded to leave the company without passing on the knowledge. This missing documentation and skills gap will ultimately create risk and result in incompetent data integration.
Initial approaches to data ingestion
A majority of data ingestion processes start manually through Excel spreadsheets or Google Sheets.
When these manual spreadsheets get too large to handle, however, businesses sometimes resort to bulk loaders. For instance, using something that allows you to put a file somewhere, where a script can then take it and upload it to a database.
This works well until the database gets too large. When that happens, businesses usually change the database. But the process of migrating the bulk loading scripts is difficult, to say the least. Oftentimes, at this point, they may look for an ETL or ELT solution instead.
This is where the question of automation comes into play.

What is poor data maturity costing you?
You may not notice it day to day. But manual fixes, rework, and brittle pipelines have a price.
Complete the State of Data Maturity survey and get a practical benchmark in about seven minutes.
When is it time for automation?
As we've seen with both processes, there comes a point where the problems become too heavy to handle manually. Most businesses will find themselves firefighting more and more.
But when exactly is it time to embrace automation? Before we answer that, here's how we define automation at CloverDX. For a large audience, automation is actually an augmented manual process. But, for us:
💡 Automation is a completely autonomous process, which can run without any user intervention at all.
Many organizations adopt the 'rule of four' for automation. Simply put, this rule states that if you need to do something four or more times, you should automate it.
By automating repeated processes, you can save valuable time. This could be weeks, months, or even years that you could spend focusing on higher leverage tasks.

Tools for integration and ingestion
In regards to either data integration or data ingestion tools, you may could adopt:
- Programmable web interface. These are very easy to configure and intuitive to use. Once you pay for a tool or register, you can use it straight away.
- Visual web designer. These are slightly more complex, but often component-based. In essence, you just wire together these pre-programmed components to help you build a transformation.
- IDE (Integrated Development Environment). Usually, you install these tools locally. Much like visual web designers, they hinge on a component-based approach. But they offer more advanced programming tools and will require more skilled users to operate.
- Programming frameworks. You can also adopt programming libraries to work and program your data flows (and can also use these in IDEs). However, these have fewer visual aids and drag and drop features. So, once again, this solution is more apt for technical staff.
Any of these options work, but your choice will be dependent on the skills you have available and your unique business needs.
Watch the full webinar
While data ingestion and integration may only have one key difference, the two processes can produce a variety of different challenges.
These challenges become apparent the bigger your integration or ingestion project becomes.
If you rely on manual processes for either, you risk falling down the trap of human error, lost documentation, and wasted resources. So, we recommend adopting automation wherever you can.
There's more detail on data ingestion, data integration, and how to approach each one in the full video: Data Ingestion vs Data Integration: What's the Difference?

Share







