
We data managers come from all walks. Relatively few of us have the title Data Manager or have data management as our primary job duty. It’s almost always an add-on responsibility—a vital role certainly, but one often layered on top of our real jobs. Some of us are software application developers and others are database administrators, data scientists, or business analysts. However, for any given data-centric activity, we are all, at heart and in practice, programmers.
We may not be programmers in the conventional sense, discarding what touch typing skills we might have acquired in our youth to concoct a potion laced with curly braces and semicolons. Rather, we are programmers in the sense that we devise, record, and test a set of instructions for getting the right data to the right place, in the right format, and at the right time to support some profitable business use. Indeed, our data management programming is likely less reliant on writing code than manipulating a sequence of rich visual interfaces.
![]()
Once we start to think of some of our data management tasks as programming, we gain a special appreciation for Larry Wall’s “three great virtues of a programmer.” Larry Wall invented the Perl programing language in 1987. It grew in popularity in the 1990s and was referred to as the duct tape that held the early internet together. Given the letter “E” in both Perl and ETL stands for Extract, it's not surprising that some data managers find Perl attractive for ETL tasks. Wall’s “Programming Perl” is arguably the most famous reference manual O’Reilly & Associates has ever published. It can be found online simply by googling “the camel book.” In this book, Wall describes the three great virtues of a programmer. These virtues are not to be confused with the three theological virtues (Faith, Hope, and Charity) or Patrick Lencioni’s three virtues of an ideal team member (Humble, Hungry, and Smart). Wall’s virtues of a programmer, to which we as data managers can also aspire, are: Laziness, Impatience, and Hubris.
A virtuous data manager is lazy
As data managers, we know all the places where our data resides. And often, for a particular need, we know it resides in the wrong place. We are wonderfully resourceful. With diligence, we can cobble together a loose collection of database queries, legacy system reports, and random CSV extracts to produce a data set that can be pushed to some other system, consumed by some other tool, or otherwise fulfill our business need. Our colleagues and bosses are appropriately grateful. Our dataset is quite useful. So much so, that they say, “Can you do this again next Monday?... and every Monday after that as well?… and can you do it before 8:00 AM so I can present it at my meeting?” The process might have been rewarding the first time, as we pathfind and discover a way to assemble the data needed. But the second time? The nth time? Not so much. It’s boring and time consuming. A “lazy” data manager will not abide this.
Wall said, “Laziness sounds like the vice of the same name, but there’s a difference. The vice is about the avoidance of immediate work. The virtue is about the avoidance of future work.”
Data integration tools support virtuous laziness and help businesses abide by data governance policies and procedures. Once we have invented a solution to a particular data problem, we can record our solution in a tool such as CloverDX and essentially eliminate the need for further manual intervention.
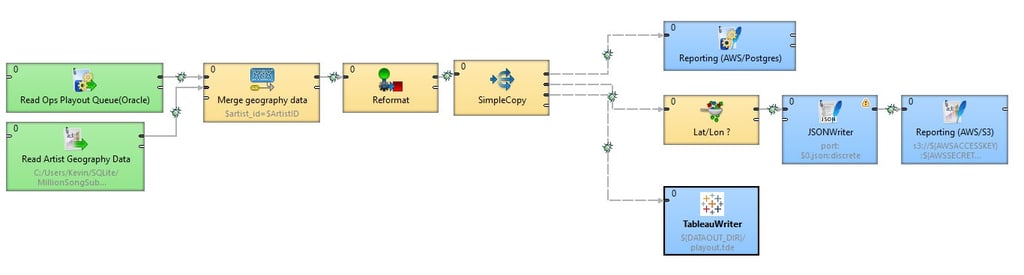
An ETL workflow can fetch data from multiple sources, filter, validate, transform, and otherwise prepare a data set for use. An advanced ETL tool can manage a workflow, deciding when to run, monitor, log all activity, and alert when things go wrong. At the pinnacle of laziness, a CloverDX workflow can even be used to create other workflows. We, the lazy data managers, are free to do more interesting work, work more befitting our intellect... more worthy of our valuable attention… ah, but we’ll cover hubris a little later.
A virtuous data manager is impatient
Again, as data managers we know all the places where our data resides. The organizations we support have many and varied uses for this data, which translate into the need to develop many and varied ETL workflows. The more of these ETL programs we create, the more familiar we get with some of the basic steps, and the more impatient we get with the time they take. We know exactly what we need to do; it just takes longer than it should. We need tools that don’t waste our time.
Wall defines impatience as “that nasty feeling you get when the computer is doing what it wants instead of what you want.” Impatient data managers who repeatedly produce countless ETL workflows are our favorite people at CloverDX. Their feedback has led to sometimes subtle, but always great product innovations:
Consider metadata. An accurate definition of the subject data is a common, vital element of all ETL workflows. Producing and managing such metadata can be tedious. Impatient data managers know that better than anyone, and have led us to features that simplify working with metadata. As a result, CloverDX can now automatically extract metadata from many data sources (and use that metadata to create equivalent tables in target systems). It automatically propagates metadata through a workflow wherever possible. CloverDX can also automatically define metadata for files it has never seen, simplifying the process of making workflows more flexible and adaptable to changes in file formats.
In another example, the CloverDX Salesforce writer components serve the impatient data manager by automatically emitting the Salesforce object IDs of all newly created objects. This seemingly simple feature pays big dividends in practice. The impatient data manager can efficiently create and store related objects in Salesforce without performing an intermediate search.
The data manager’s primary goal is to define a data workflow, ensuring data gets moved correctly and efficiently from point A to point B. The mechanics of when the workflow is launched are often secondary, and an impatient data manager could rightfully expect his tools to take care of such details.
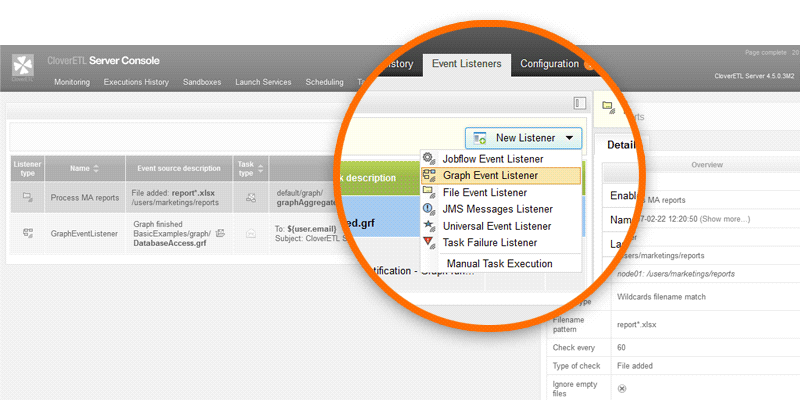
The CloverDX scheduler will launch, monitor, log, and alert jobs chronologically. CloverDX event listeners will do the same based on triggers in the data environment, such as the arrival of a file on an FTP site, a message on a queue, or the arrival of an email. CloverDX Data Services can automatically create and manage web APIs for any CloverDX workflow allowing a workflow to be called on demand.
A virtuous data manager has hubris
Wall suggests that the final great programming virtue is hubris, which he defines as “the sense that, with the right tools, you can do just about anything.” I suspect that hubris is a part of what led many of us to take on the role as data managers in addition to our regular jobs. Whether the task is to keep our ERP and CRM in sync, ingesting data from new clients, or preparing data for analytics, we look at the current processes and think we could do it better, faster, and cheaper.
Are you a virtuous data manager?
Do you want to be lazy, impatient and hubristic? Why not contact us right now? CloverDX exists to help all data managers—those who are virtuous and those who strive to be.
Share




