
Ever wondered what to do with those annoyingly slow operations inside otherwise healthy and fast transformations? You’ve done everything you could do to meet the processing time window, and now there’s this wicked API call that looks up some data, or a calculation that just sits there and takes ages to complete, record by record, dripping like water from an old faucet. And yet, all that sits on a beefy machine that’s capable of running dozens of these operations.
So naturally, you’d go from this:

A painfully slow operation in the middle blocks the processing
To something like this (old fashioned now!):
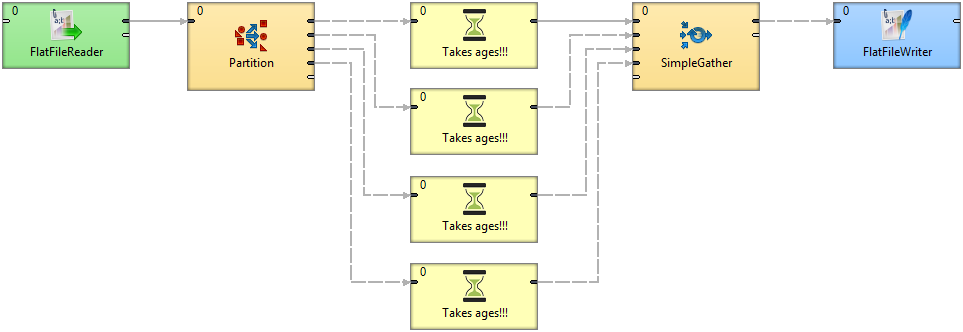
Branching the transformation brings some level of parallelism
This approach gets you the desired increase in throughput, for sure. You split the stream into four parallel branches in a round robin, wait for those slow (now parallel) operations to finish and then collect everything back into a single file.
There are numerous drawbacks to branching as a way of parallel execution:
- Difficult to scale up or down: You have to change the transformation quite a bit to switch from the four branches here to let’s say eight, given you want to move onto a more powerful Server
- Nightmare to keep configurations consistent: Usually you have multiple components in that parallel sequence. Imagine changing a parameter or some mapping in a dozen components every time you want to change something!
- Doesn’t scale to multiple Cluster nodes: This design does not scale to multiple nodes in a Cluster, yet that’s exactly what you want to design towards; future-proof and universally scalable transformations that run on a single Server just as they spread across multiple nodes.
Do these troubles ring a bell? I bet they do.
Data Partitioning Helps Scale Properly
Let’s look at Data Partitioning, a feature introduced in CloverDX Server Corporate version 4.2 and Cluster. It’s an elegant answer to the above issues for performance scaling.
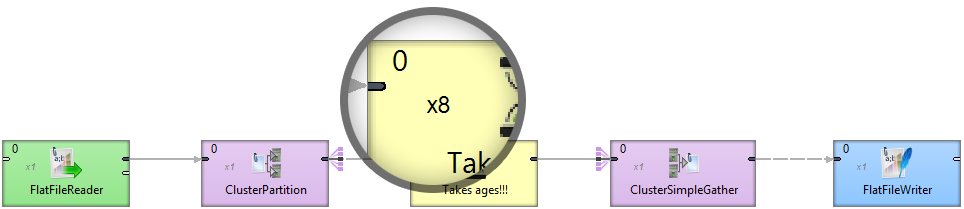
Finally, using Data Partitioning to run a slow component in 8 times parallel
With Data Partitioning, you don’t create additional branches. Neither do you have to jump to a completely different design philosophy, convert to a different job type, use add-ons or even a different engine.
You simply specify the number of instances you want a particular component or bunch of components to spawn. That’s it. In the background, CloverDX will start multiple workers to handle the operation in parallel for you.
The beauty lies in the simplicity of changing the level of parallelism and keeping the transformation clean without duplicating components and their configurations.
Advantages of Data Partitioning
Data Partitioning actually solves performance scaling issues on multiple fronts:
- Clean design, no duplication. You configure all operations only once, no need to meticulously change a parameter in all components every single time
- Scales to Cluster. Transformations designed in this way require no additional modifications, either in configuration or actual design, if you decide to deploy them on a multiple node Cluster. All Cluster controls for spanning transformations across multiple nodes are fully compatible with Data Partitioning.
- Maximize use of available hardware: Such an easy way of running operations in parallel will leave you wanting to design transformations that utilize the most of your computing platform.
- Finish within your processing time window. As data volume obviously grows almost daily, days remain only 24 hours long no matter what. Increasing performance is a must and data partitioning can help you squeeze out the extra performance.
- Dynamically control number of workers: You can use a standard parameter to set the number of workers for a component dynamically, let’s say in a parent jobflow. A bit niche use, but still, might prove quite useful.
What Are The Best Uses for Data Partitioning?
Data Partitioning can easily speed up your processing times by factors counting in tens or twenties. It makes it extremely easy to try and check what happens when you execute operations in parallel. Let’s look at a few examples where this is particularly useful.
- Increase throughput of Web Service and API calls. These are the most obvious ones. Typically a REST or SOAP call is easy to make but the roundtrip easily takes seconds for each record or batch. Watch this video showing more than 15 times quicker processing time by running 50 requests to Yahoo Weather API simultaneously. However, keep in mind there are limitations to the typical APIs - daily limits, pre-paid queries, etc.
- Parallel JSON and XML parsing or formatting, especially when compressed. Parsing or writing structured text formats in and out from data records for use elsewhere takes processing time. What’s more important, I/O might not be the bottleneck here as these can be effectively compressed so that most of the work is done by the processor. As these are inherently single-threaded operations, splitting the file into chunks and processing in parallel makes a lot of sense.
- Boost performance with parallel I/O. CloverDX has a few interesting features to utilize high-throughput disk drives designed for concurrent use. First, check partitioned sandboxes - a way of storing large files chunked in multiple locations (either just folders or mounted drives, or better yet on different nodes). Data Partitioning will then naturally pick up the file distribution and process the individual chunks locally and in parallel, minimizing network transfers and maximizing local I/O. Even without partitioned sandboxes, you can read a file in multiple streams at once with ParallelReader.
- Concurrent CPU-intensive calculations. Although it might sound fancy and scientific, you don’t need to be calculating ballistic trajectories to have a piece of code that takes some time to process. You might be doing some heuristics to find proper format of a date, or a lookup to standardize a value, or a bunch of Validator rules. All that takes time to process on each record and utilizing more CPU cores by running a few in parallel is a really cheap optimization with Data Partitioning.
- Distributed sorting. This one might be tricky but there is a case for running sorting jobs in parallel. The idea is to split the data into multiple chunks, pre-sort those individually, either in memory on disk, and then use ClusterMerge to properly merge the intermediaries.
However, no matter how great the above examples might turn out, don’t miss the last chapter of this blog for a list of things to consider when going parallel.
Where Is It Available?
Data Partitioning has been around for a while now in CloverDX Cluster. With the release of 4.2 in June 2016, we made this available to Server Corporate as well.
So, to get Data Partitioning all you need is to upgrade your Corporate Server to the latest version and read on to learn how to use it.
You can also try it on our CloverDX Server Demo instance. Go to Try CloverDX to get the latest Designer and use the built-in Server examples to play around.
It is NOT available in Designer running local projects (you can design but it won’t run).
How Do I Use It?
You will need to grasp a bunch of concepts borrowed from Cluster to use Data Partitioning but none of it is rocket science. Here are a few basics:
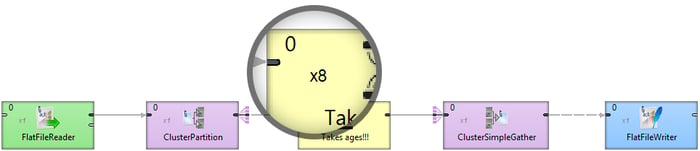
- To split an input stream across multiple workers, use ClusterPartition. You don’t need to set anything there. The number of workers is actually determined by actual components, not here. You can alternatively use ClusterLoadBalancingPartition that tries to maximize the usage of individual workers instead of the standard round robin.
- Set level of parallelism by setting the allocation property of a component (right-click > Allocation, or Edit component and you’ll find Allocation under Common). Allocation is actually quite a powerful concept in Cluster but for simplicity you only need to use “Number of workers”. Allocation propagates through the transformation itself, so typically you only need to set it once.
- To collect data from individual workers back into a single stream, use ClusterSimpleGather (surprisingly similar to SimpleGather!) or ClusterMerge if you care about ordering the records as they come from workers.
- You can process partitioned files with Data Partitioning, e.g. splitting a large file across multiple disks and then transforming individual parts in parallel. There’s a useful reading about partitioned sandboxes and parallel data processing in general that you can read to learn more.
Things to Consider When Going Parallel
Obviously, not everything can be run in parallel and you don’t always want to overload your servers with arbitrarily greedy transformation graphs. So consider these:
- High latency, long round trip operations are the best candidates. These are the safest and most impactful optimizations Data Partitioning will give you. Web Service API calls or DB lookups that have to travel long distances and yet generally don’t consume system resources are easily parallelized.
- Have mercy with the “other” endpoint. However, to the previous point, always consider the other end of any network connection. Is that API you’re calling a hundred times within a second built to scale like that?
- I/O and networks are typical bottlenecks. Unfortunately, these will hardly benefit from running in parallel. Always measure what causes your transformation to run slowly. In general, if both CPU and I/O are idling and your jobs still run slowly, jump to Data Partitioning. However, if disks or network are busy and barely keeping up, you must seek optimizations elsewhere. Bummer.
- Be modest, consider other jobs running on the same Server. Your job would seldom be the only thing the Server has to deal with at any particular time. Decide whether starting twenty additional workers for your job will do larger good to the other tasks that need to finish reliably and on time.
- Some tasks are hard or even impossible to optimize. Not everything can be processed in parallel and even if it can, maybe it’s not the best idea to do so. For example: While in certain cases it might be feasible to split sorting onto multiple workers and then merge results, you need to consider I/O capabilities and available memory before going parallel.
- Parallel jobflow or in-transformation parallel components? Typically, you want to run multiple parametrized jobs if you’re processing multiple datasets that can be processed independently - e.g. thousands of XML files that need to be loaded into a database. Data Partitioning is helpful when you only need to get down to individual operations on data. Something that operates on a single data set or stream, but part of it can be distributed among multiple nodes or just processor cores.
- And lastly: Optimize first, do not use brute force. Often, there are clever ways to make your transformation run faster while using less memory, network bandwidth, etc. Always explore those options first. Use Data Partitioning wisely, think of it as your last resort.
That’s all for this little introduction to the fabulous world of turning regular transformations into parallel heavens.
Watch a cool video on Data Partitioning and while you’re at it, be sure to check out other awesome features of CloverETL 4.2.
.webp)
Share







