Data onboarding for SaaS
A data ingestion tool that handles any format, from any source
Build reliable data ingestion pipelines to onboard client data without starting from scratch each time.
Handle different file formats automatically, saving hours of manual Excel work and custom development.

Speed up ingestion to your platform
Build data ingestion pipelines that handle any format, from any source
If you regularly receive files in different formats that you need to standardize to your spec - at scale - then CloverDX can help speed up the data onboarding process and help you deliver reliable data.
- Build transparent, automated data pipelines to onboard client data faster
- Handle any file format, including Excel, CSV and flat files, even when columns or formats are different
- Create customized data validation and transformation rules
- Eliminate reliance on development teams
- Empower business users to manage data ingestion and data mapping processes in dedicated, user-friendly interfaces
- Automate data ingestion end-to-end, from detecting arrival of new files to loading to target






Streamline processes
Automate repetitive ingestion work
Don't let the engineering team be a bottleneck to data ingestion. Free up the technical team's time by enabling business users to be part of the process.
- Build a single data ingestion pipeline that automatically handles variations in input and can standardize different file formats automatically
- No need to build a new pipeline for each new client or data source
- Empower business users to manage parts of the onboarding process, from drag-and-drop data mapping to reviewing data before it's loaded

 "We cut the time it took them to do those conversions by maybe a fourth or a third. When you’re talking about 5 days to convert a customer, and this automation takes a day off, that’s a pretty big chunk from my perspective."
"We cut the time it took them to do those conversions by maybe a fourth or a third. When you’re talking about 5 days to convert a customer, and this automation takes a day off, that’s a pretty big chunk from my perspective."
- Bryan Kahlig, Senior Director, Product Development at Zywave
Improve data quality
Validate and clean data automatically
When it comes to delivering client migrations, CloverDX helps increase trust and credibility by helping you present accurate data to customers from the start.
Gain trust pre-sale. Deliver on your promise post-sale.
- Increase data accuracy with automated validations
- Speed up onboarding so customers see value fast
- Give non-technical domain experts access to review and edit data before ingestion
- Handle ongoing data integrations between client sources and your platform reliably so customers get accurate data

Handle increased volume
Scale data ingestion volume without scaling your team
CloverDX can handle large amounts of data and scale easily to keep up with your data ingestion needs.
- CloverDX pricing isn't based on data volume, so you don't pay more as your data volumes grow
- Reduce manual effort so you can onboard more data without needing to increase headcount
- Automate data ingestion to handle more data from more sources easily
Request a demo and see how CloverDX can help you onboard more data and grow your business.

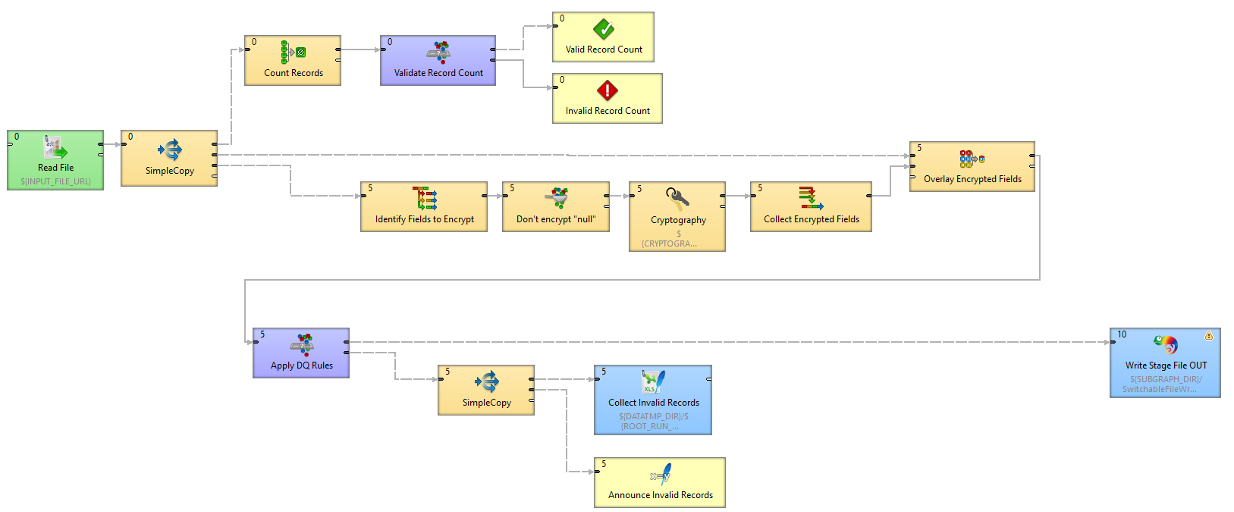
How to build an end-to-end automated data ingestion pipeline in CloverDX
See a step-by-step walkthrough of how a data onboarding pipeline in CloverDX works, and how it can handle your data onboarding on autopilot, no matter how many different clients you're getting data from.
Automating customer data onboarding
Onboard more customers, more quickly, without needing to tie up (or hire more) expensive engineering resource.

Webinar: Data ingest for faster onboarding
When your business is built on ingesting data from many customers, in many different formats, how do you scale up the volume of data and clients you can support – without adding headcount? See how you can automate data ingestion and reduce developer spend.

How Zywave freed up engineer time by up to a third with data automation
For insurance agency software provider Zywave, customer data onboarding was a time-consuming headache.
Bespoke, hand-coded processes had a lot of technical debt and were difficult to maintain, taking up a lot of engineer time.
Automating the data process with CloverDX means that instead of manual steps, engineers can now push a button and trust the process is going to work, freeing up significant time.
Customer onboarding time has reduced by at least 20%, and the previous bottleneck in the process has been removed.
“The onboarding process is our first chance at making a good impression with our customers after the dollars are already spent. And CloverDX gives us a tool to be able to move faster.”
- Bryan Kahlig, Senior Director, Product Development at Zywave

How HireRoad were able to triple their customer base, without needing to add resource
HR SaaS software PeopleInsight, part of HireRoad's cloud-based talent management platform, needed to speed up their customer data onboarding to handle more clients, and to provide more up-to-date data.
The previous process was ad-hoc and time consuming. But with CloverDX now handling the automated data workflows, that previous manual work is now removed.
Anywhere between 45 and 60 minutes of manual effort, per client, per day, is now down to zero manual work required, as the jobs are just scheduled and run automatically.
"We were easily able to triple our customer base without a need to add resources."
- Andrew Peralta, Director of Platform and Development at HireRoad

What should you look for in a data ingestion tool?
Looking for a data ingestion tool that can speed up onboarding or handle growing data volumes? Here’s what to consider in your next solution—and how to recognize when your current approach may be reaching its limits.
