
Hierarchical data structures - JSON

Historically, there were 2 options to read JSON files prior to CloverDX 5.6. Following 5.6 we introduced a new option – to work with JSON directly in CTL. In this article, we’ll take a look at different ways of handling JSON in CloverDX and discuss their pros and cons.
The component approach is one you might want to take whenever data are stored either on local or remote data storage. The latter, the CTL one, you can use when data are already loaded into job’s data stream. This may include a situation when data are coming from MongoDB or as a result of HTTP response.
JSONExtract (“streaming reader”)
 Built for performance, this component allows you to read huge structures with almost constant memory usage, considerably faster than using other methods.
Built for performance, this component allows you to read huge structures with almost constant memory usage, considerably faster than using other methods.
JSONExtract should be the default method to read JSON document. In most cases, it offers by far the best performance and a visual, drag&drop user interface for mapping JSON structure into CloverDX metadata, broken down to individual objects. It is most frequently used to read complex JSON documents or large files.
As an example, let’s take a look at the following JSON document that stores a collection of Customer object and associated Accounts.
[ {
"id": 11651,
"fullName": "Donn G Marola",
"streetAddress": "256 Rio Clara Dr",
"city": "Chicago",
"postalCode": "60610",
"state": "IL",
"country": "USA",
"email": "donn-marola@example.gov",
"phone": "670-018-7377",
"accountCreated": "2014-08-12",
"accounts": [ {
"accountId": 3567361088,
"accountBalance": 9453.563,
"created": "2014-09-21"
} ],
"isActive": true
} , {
/* ... */
} ]To read customer data and all accounts, the mapping could look like this: 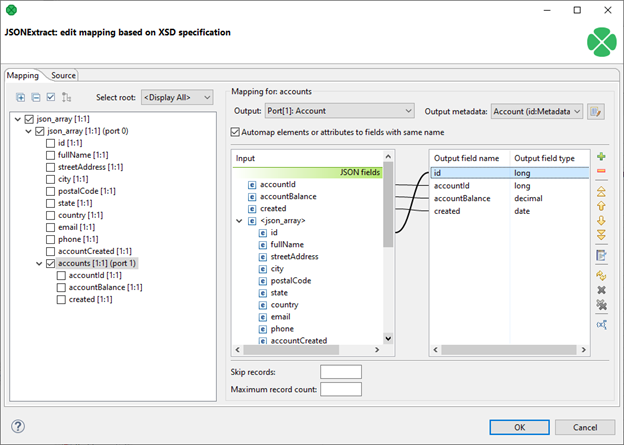
Visual mapping makes it very easy to see which parts of the document are mapped and where are they mapped to. Another important information the editor provides is which datapoints are used to form an output from the component, this allows you to keep track of the document structure by mapping key fields from parent/child records, generate surrogate keys using sequences and more.
Since JSONExtract uses streaming parser (SAX) to process documents, it will very easily handle large documents, even many gigabytes in size, with very low memory overhead.
Arrays of primitives can be extracted as CloverDX lists. Since release 5.11, JSONExtract is fully compatible with variant data type and is capable of extracting whole (sub)trees of JSON documents into it. Handy in situations where you need to work with specific data types but still need to transfer part of a document as is.
Where JSONExtract falls short are cases where attribute names in JSON object change from document to document or are part of information. For example consider a document which provides exchange rates between different currencies like so:
{
"snapshot": 1449877801,
"base": "USD",
"rates": {
"AED": 3.672538,
"AFN": 66.809999,
"ALL": 125.716501,
"AMD": 484.902502,
"ANG": 1.788575,
"AOA": 135.295998,
"ARS": 9.750101,
"AUD": 1.390866,
/* ... */
}
}In the above example, you’d have to create a field for each currency code and map it separately. This is not a viable option since there are hundreds of currencies, so the mapping would be very complex and hard to maintain. It would also result in a single record with one field per currency which is usually not desirable – a better way would be to read currencies as pivoted data. For this purpose, use the next component.
Pros
|
Cons
|
JSONReader (“XPath reader”)
 JSONReader provides additional flexibility in data parsing and mapping because of XPath expression support and is a better choice when static mapping may be a limiting factor. The cost of this flexibility is much higher memory consumption (to build and maintain DOM) and a user interface that does not allow visual mapping but rather requires providing xml-based configuration.
JSONReader provides additional flexibility in data parsing and mapping because of XPath expression support and is a better choice when static mapping may be a limiting factor. The cost of this flexibility is much higher memory consumption (to build and maintain DOM) and a user interface that does not allow visual mapping but rather requires providing xml-based configuration.
To efficiently read the exchange rates file from the previous example, JSONReader’s ability to query DOM and call XPath functions to map object attributes into the output without having to define a fixed mapping for each currency. This will work for any number of currency codes and will not require any changes in metadata when currency codes are added or removed.
<Context xpath="/root/object/rates/*" outPort="0">
<Mapping xpath="name()" cloverField="currency" />
<Mapping xpath="." cloverField="rate" />
</Context>This mapping will result in many record tuples containing currency name and its conversion rate instead of one long record JSONExtract would’ve provided.
JSONReader have many powerful abilities, like axis DOM traversal, support for conditional statements and all XPath 1.0 functions.
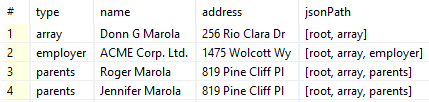
Consider this mapping configuration and dataset:
<Context xpath="//*[address]" outPort="0">
<Mapping xpath="name()" cloverField="type" />
<Mapping xpath="fullName|legalName" cloverField="name" />
<Mapping xpath="address" cloverField="address" />
/* ... */
<Mapping xpath="ancestor-or-self::*/name()" cloverField="jsonPath" />
</Context>[{
"fullName": "Donn G Marola",
"address": "256 Rio Clara Dr",
/* ... */
"employer": {
"legalName": "ACME Corp. Ltd.",
"address": "1475 Wolcott Wy",
/* ... */
},
"parents": [{
"fullName": "Roger Marola",
"address": "819 Pine Cliff Pl",
/* ... */
} , {
"fullName": "Jennifer Marola",
"address": "819 Pine Cliff Pl",
/* ... */
}]
}]Which results in the following output. It is worth mentioning, metadata field jsonPath is of container type list. Also notice, how each entity’s level or type differs. That is because the selection is not predicated neither on path or node type but existence of specific node element – address.
Pros
|
Cons
|
Variant datatype
CloverDX 5.6 had a significant addition to CTL language. Native support for hierarchical data structures using new data type – variant. This release also introduced a set of functions for serialisation and deserialization, search and other tools allowing more efficient work with JSON documents.
Unlike previously discussed components, the new CTL addition cannot be used to parse data from filesystem directly but can be invaluable when working with REST-based web services which frequently use JSON as payload or to build structured document in transformations.
Calling a CTL function parseJson() will parse a JSON document provided as a string, producing variant representing original JSON’s data in a way which is both traversable and searchable from CTL. Result will also preserve all of CloverDX datatypes and falls back to string if any other conversion is not possible.
JSON arrays are converted into lists, objects into maps. These containers then serve as means of traversal through variant. To access and modify data from Customer object from our first example (string representation of the document already resides in $in.0.content metadata field):
variant json = parseJson($in.0.content);
/* Data is a list, so we can access objects as list elements. */
integer customerCount = length(json);
/* First customer. */
variant customer = json[0];
/* Each object is a map, to access object property use map syntax. */
variant fullName = customer["fullName"];
/* Alterntively, we can compose more complex path to an element directly. */
fullName = json[0]["fullName"];
/* To convert from variant into primitive type we can use casting. */
string fullNameStr = cast(fullName, string);
/* Or directly without temporary variables... */
fullName = cast(json[0]["fullName"], string);
/* Modifying an element of an object. */
json[0]["fullName"] = "Albert Einstein";
/* Adding a new object property is just as easy. */
json[0]["numberOfAccounts"] = length(json[0]["accounts"]);
/* Deserializing variant into json. */
$out.0.content = writeJson(json);Working with variant is a complex topic and CTL provides great deal of functionality that allows you to easily parse, investigate and manipulate any complex data structure. This flexibility comes at a cost though – the need for writing code and higher memory utilisation.
Pros
|
Cons
|
Summary
We presented three different ways of JSON document ingestion process in CloverDX. All of them have their uses with different pros and cons. Choosing the right way can make the implementation faster and solution easier to maintain.
In general, you can use the following guidelines to help you select which way to use:
- If you need to process large documents (>30 MB), always use JSONExtract to guarantee best performance and low memory consumption.
- If you have complex document structure (deeply nested documents, many attributes, etc.), using JSONExtract is preferable since it allows you to use very comfortable mapping user interface.
- If you need searching within the document or your task can be easily accomplished by XPath, use JSONReader. Be aware of the file size to ensure good performance of your graph.
- For large documents, where complex queries are necessary it is possible to use JSONExtract to convert this document into smaller variant fragments, then use CTL in Transformation components to implement more advanced queries.
- If you need to process complex JSON document, splitting it into many small elements would require large number of joins (for example to work with objects from different parts of the document), use CTL. Again, always consider the file size.
- When JSON document was already ingested in form of a string (e.g., as HTTP response, result of MongoDB query, …), use variant to read and manipulate its internal structure.
More from Tech Blog
-
CloverDX Server diagnostics with ChatGPT or Claude via MCP
Administrating a healthy CloverDX Server usually means correlating information scattered across performance logs, job tracking tables, execution logs,... AI -
Data Quality Examples on GitHub
As our first set of examples, we published a project called DataQualityExamples which demonstrates how users can address their data quality issues with... CloverDX How-To -
Introducing CloverDX Examples on GitHub
We’re excited to introduce the CloverDX Examples repository on GitHub. The repository is a growing collection of helpful and practical examples designed to... CloverDX How-To -
Sending emails via Azure Communication Services SMTP
There are many situations where it is helpful to get a message from your active pipelines. These may include logs, summaries of successful completion, or... Cloud -
Connecting to REST APIs (OpenAPI)
Connecting to REST APIs is a crucial aspect of modern data integration, and the REST Connector in CloverDX provides a streamlined approach. The video below... RESTConnector -
Performance tuning: How to troubleshoot database-related performance issues in CloverDX
Performance is undoubtedly one of the key factors when running data transformations. In this article, we will look at how to troubleshoot database-related... Performance
Visit CloverDX Blog
-
How financial services firms use automation to cut reporting from days to half a day
-
Data integration after an acquisition: How fast-growing companies stay in control
-
Boomi vs CloverDX for enterprise data integration
-
Boomi Alternatives: A Complete Guide (2026)
-
Why SaaS engineers are stuck doing manual customer data onboarding – and how to fix it

