
Organizing large projects: Separating Configuration and Data
When you start working on a CloverDX project, you'll notice that it comes with a predefined structure see here for more details. This structure works really well for small projects and projects that you intend to run from within the CloverDX Designer.
However, keeping everything in one place can cause issues as your projects grow into bigger pipelines managed on CloverDX Server. Let's have a look at a few very simple techniques that will help you organize larger projects.
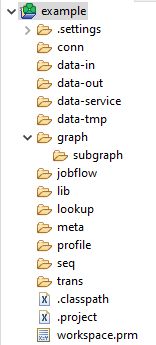
Standard CloverDX project structure
The Three Entities to Separate
As projects expand and increase in complexity, it's recommended to distinguish between three key components:
- Data
- Configuration
- Codebase
Data
By default, CloverDX let's you put your data files to folders labelled "data-in," "data-out," and "data-tmp" inside the project (or sandbox on the Server). This setup is convenient for small projects and initial development phases. However, as your project matures, you may encounter some issues:
-
Performance Problems: A high volume of data files in the sandbox can slow down various aspects of your project, such as project synchronization in CloverDX Designer, project export via the server's user interface and API, and navigating through your project in the Designer or the server UI.
-
Storage Limitations: Sandboxes are typically saved on storage systems not designed for long-term data archival. Over the long haul, these storage systems may lack redundancy, capacity, and suitable backup policies for your files.
-
Deployment: Combining data with the code base in a production environment complicates deployment processes. Furthermore, it makes rollbacks and version control more challenging.
Separating data out of the project folder
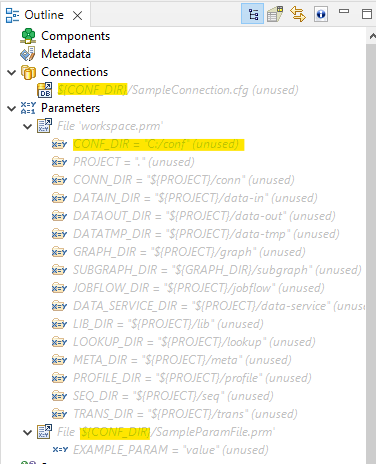
There are two common approaches to address these issues. The first is to modify parameters like DATAIN_DIR, DATATMP_DIR, and DATAOUT_DIR (found in the "workspace.prm" parameter file) to specify more suitable locations for your data files. Typically you would use shared mounted folders or high-volume storage mounted separately to the Server.
The second approach is to create a dedicated sandbox just for data, usually using “_data” as the suffix appended to the original sandbox name.
Configuration
Configuration settings and parameters can generally be categorized into two types: those specific to a particular process, job, or sandbox, and those that could be shared across multiple projects. Parameters used for establishing connections to various systems (like URLs and credentials) are prime candidates for sharing. Doing so allows you to manage shared configuration centrally, simplifying tasks such as deploying code (especially when moving code between environments) and making connection-related changes.
Using parameters to separate configuration
To link parameter files for shared configuration, use a parameter like "CONF_DIR" in the URL. This approach allows you to switch between different configurations easily.
Alternatively, you can explore other CloverDX features like Azure Key Vault and AWS Secret Manager to securely store credentials and other shared configuration information.
Codebase
Simplifying your code can be achieved by breaking it down into smaller, more manageable pieces, such as functions or subgraphs in the case of CloverDX graphs. Creating subgraphs and functions that abstract recurring code segments promotes code reuse, reduces the likelihood of bugs, and accelerates development. This practice aligns with the "Don't Repeat Yourself" (DRY) principle.
Using Libraries to organize your codebase
You can move shared subgraphs to a separate sandbox, however using CloverDX's libraries can enhance the development experience when working with shared code components. Additionally, you can share sections of CTL scripts by saving the code in a .ctl file and using the "import" directive.
Lastly, you can leverage libraries created by others available in the CloverDX Marketplace. These libraries offer prebuilt connectors that can significantly streamline your projects, especially when connecting to popular cloud platforms.
Conclusion
By separating your data, shared configuration, and shared code, you can manage your CloverDX projects more effectively as they become complex. This practice enhances performance, simplifies configuration management, and promotes code reuse, ultimately making your development process smoother and more efficient.
More from Tech Blog
-
CloverDX Server diagnostics with ChatGPT or Claude via MCP
Administrating a healthy CloverDX Server usually means correlating information scattered across performance logs, job tracking tables, execution logs,... AI -
Data Quality Examples on GitHub
As our first set of examples, we published a project called DataQualityExamples which demonstrates how users can address their data quality issues with... CloverDX How-To -
Introducing CloverDX Examples on GitHub
We’re excited to introduce the CloverDX Examples repository on GitHub. The repository is a growing collection of helpful and practical examples designed to... CloverDX How-To -
Sending emails via Azure Communication Services SMTP
There are many situations where it is helpful to get a message from your active pipelines. These may include logs, summaries of successful completion, or... Cloud -
Connecting to REST APIs (OpenAPI)
Connecting to REST APIs is a crucial aspect of modern data integration, and the REST Connector in CloverDX provides a streamlined approach. The video below... RESTConnector -
Performance tuning: How to troubleshoot database-related performance issues in CloverDX
Performance is undoubtedly one of the key factors when running data transformations. In this article, we will look at how to troubleshoot database-related... Performance
Visit CloverDX Blog
-
How financial services firms use automation to cut reporting from days to half a day
-
Data integration after an acquisition: How fast-growing companies stay in control
-
Boomi vs CloverDX for enterprise data integration
-
Boomi Alternatives: A Complete Guide (2026)
-
Why SaaS engineers are stuck doing manual customer data onboarding – and how to fix it

