-
Product

- Solutions
-
Customers
Discover how Gain Theory automated their data ingestion and improved collaboration, productivity and time-to-delivery thanks to CloverDX.
Read case study


Data importers/exporters require data in perfect shape. Unfortunately, the chances are you don't have the luxury of that. The reality is often messy and requires work before you're ready to finally load the data into a new CRM.
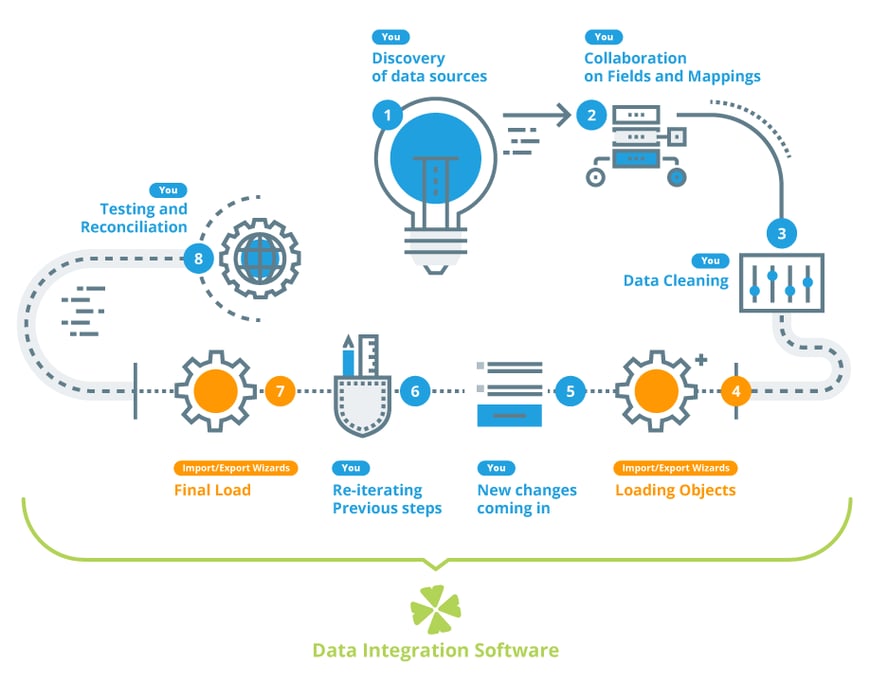
During migration, you often perform repetitive tasks and steps that have to be carried out in a specific order: from moving files and loading them as attachments, through multi-step data load sequences (e.g. Accounts > Contacts > Custom objects), all the way to testing and clean-up.
Instead of carrying out actions manually, put them into orchestration job flows. A job flow allows you to design and then repeatedly execute a logical sequence of operations and eliminate potential risk of error, compared to planning and manually executing each step.
Data is the biggest asset of any company. Handling it correctly requires close collaboration and trust between stakeholders, users and implementors.
Quickly uncover the real nature of the source data by using Data Profiler. There is often a disconnect between user beliefs and reality. Discover picklist values actually in use, find unexpected and
Discover issues before the data migration even starts. Data collected in CRM systems gets quite messy over time despite what their users will tell you. It's not just typos and inaccuracies. Several rounds of process changes and numerous CRM customizations create gaps and inconsistencies. Eradicate them to make the new CRM consistent again.
Migration is a great time for a company to stop, rethink and actually fix the quality of their CRM data. Don't miss this opportunity.
Present users with automatically generated reports from Data Quality Validator and introduce measures to repair issues - point out missing data, standardize picklist values, validate phone and email addresses. However, fixes requiring user inputs might take several rounds. With CloverDX you can easily re-run the verification and healing process and iteratively bring back credibility to the CRM data.
Keeping mappings in separate shareable documents helps all involved parties successfully define and understand how data will move from the legacy system to the new one.
With CloverDX you can set up generic jobs to use externally defined mappings in human-friendly form (e.g. Excel). This allows better communication between involved parties and faster change management.
Fully automate loading of binary attachments such as contracts, emails or legacy quotes. Along the way, you can also automate the renaming and moving of files to the right location, augmenting records with metadata and transparently handle errors.
CloverDX doesn't force you to code. However, it gives you the option to do so whenever you feel a problem can be better solved by a few lines of code. You can always jump back and forth between visual editors and code. Multiple if-elseif statements, iterating over multi-value fields or smart type conversions can move you forward and keep the process simple.
You can set up additional job flows that check and reconcile data after you've executed the main migration.
Ensuring that records make it successfully to their destinations, and leaving no data behind, secures user's trust in the whole operation.
Design your migration process as an automated job flow and you can retry and test the whole process as many times as you need. This becomes invaluable during preparations for the finale of the project.
With automation, you can time test runs on the full data set and know exactly how long a production switch will take you. CloverDX uses Bulk API to maximize throughput for large datasets.
When the big day comes, the only thing left is a press of a button.
Retaining relationships between entities such as Contacts and Accounts requires a correct order of operations and remapping legacy IDs onto newly-inserted Salesforce Object IDs.
Chain dependent inserts into a single sequence of operations without unnecessary intermediate steps . The pass-through nature of CloverDX operations allows you to retrieve new Salesforce IDs from one step and use them to replace corresponding legacy IDs in the next one to properly maintain relationships when data is loaded in Salesforce. All in a single run.
Adopting CloverDX to carry out the data migration and transformation part of the project can greatly reduce errors, shorten turnaround times and save your time for other tasks.