
A How-to Guide on Parsing List Data in XML and JSON with CloverDX 4.1

Parsing of XML and JSON data is an important task in data integration because the majority of today's APIs and Web Services are built around these two formats. CloverDX has JSONExtract and XMLExtract components which do just that.
With the release of CloverDX version 4.1 we added the ability to parse JSON array elements and repeating elements in XML (sequences) directly into lists in CloverDX records.
A metadata field usually holds only a single value of predefined data type (string, integer, etc.). However, you can switch the field to “list” or “map” mode which makes it hold an array of values (of the same data type). Some components can work with these directly, or you can easily manipulate lists in CTL.
You can check out our documentation for finer details.
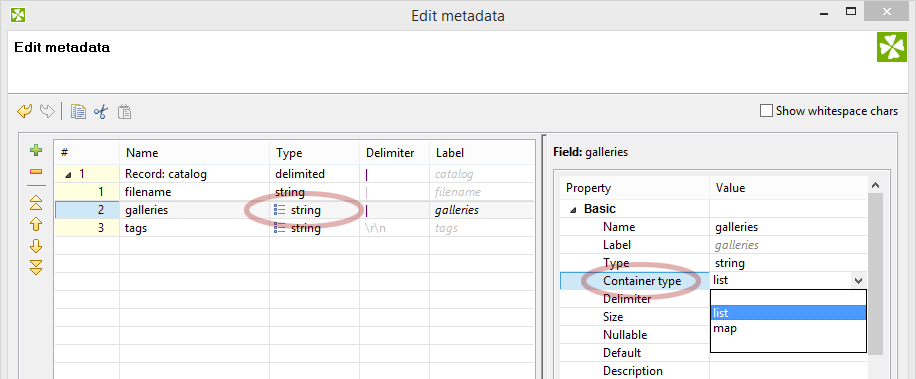
Look at “galleries” and “tags” in these simple examples:
JSON
{
"filename": "dsc_74532.jpg",
"galleries": ["family", "2015"],
"tags": ["summer", "children", "Peter", "Mary"]
}
XML
<?xml version="1.0" encoding="UTF-8" ?>
<catalog>
<file>
<filename>dsc_74532.jpg</filename>
<galleries>family</galleries>
<galleries>2015</galleries>
<tags>summer</tags>
<tags>children</tags>
<tags>Peter</tags>
<tags>Mary</tags>
</file>
</catalog>
You can see these have multiple values that need to be parsed and processed. Previously, you had to work around such multi-value elements by having multiple record streams (and therefore multiple edges) instead of using multi-value fields.
See how it looks with lists instead of multiple record streams:
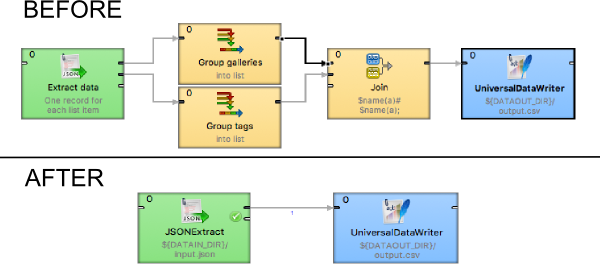
As you can see, we've saved a component for each multi-value element, plus a 'join' component to put everything back together. Undoubtedly, it can save a lot of time in development when incoming data structures change. And of course, this improvement also positively affects performance.
Here's how it works...
Let’s see how the new list mapping feature works for the sample XML data above (galleries and tags).
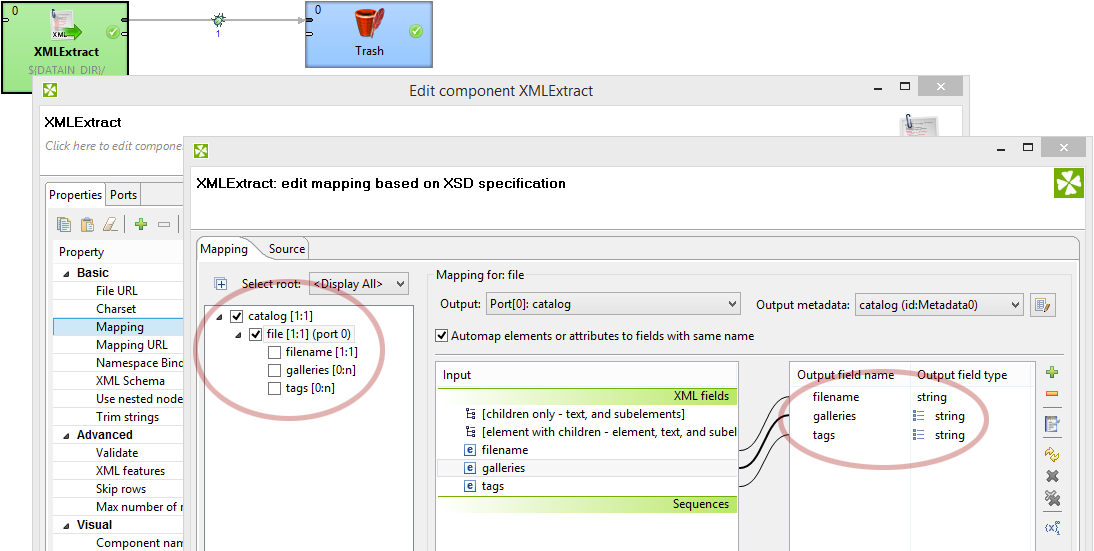
The mapping looks simple, just like if we were dealing with regular single value fields. For obvious reasons this only works if the repeating element does not contain additional sub elements (i.e. if is not a structured element on its own).

More from Tech Blog
-
CloverDX Server diagnostics with ChatGPT or Claude via MCP
Administrating a healthy CloverDX Server usually means correlating information scattered across performance logs, job tracking tables, execution logs,... AI -
Data Quality Examples on GitHub
As our first set of examples, we published a project called DataQualityExamples which demonstrates how users can address their data quality issues with... CloverDX How-To -
Introducing CloverDX Examples on GitHub
We’re excited to introduce the CloverDX Examples repository on GitHub. The repository is a growing collection of helpful and practical examples designed to... CloverDX How-To -
Sending emails via Azure Communication Services SMTP
There are many situations where it is helpful to get a message from your active pipelines. These may include logs, summaries of successful completion, or... Cloud -
Connecting to REST APIs (OpenAPI)
Connecting to REST APIs is a crucial aspect of modern data integration, and the REST Connector in CloverDX provides a streamlined approach. The video below... RESTConnector -
Performance tuning: How to troubleshoot database-related performance issues in CloverDX
Performance is undoubtedly one of the key factors when running data transformations. In this article, we will look at how to troubleshoot database-related... Performance
Visit CloverDX Blog
-
Boomi vs CloverDX for enterprise data integration
-
Boomi Alternatives: A Complete Guide (2026)
-
Why SaaS engineers are stuck doing manual customer data onboarding – and how to fix it
-
Legacy ERP. Hundreds of suppliers. Dozens of different data formats. How one distributor made it all work.
-
Beyond rules: How AI is transforming data classification, anonymization, and anomaly detection

