Users often need to retrieve data from a data source which does not contain this related data but is easily defined. Thus, it is important to be able to add further information to your source that is not already present in the file e.g. time stamps or name of excel sheet - enrich data. This additional information simplifies further data processing.
For example:
All this information can easily enrich the read data in CloverDX by using the auto-filling functionality.
Auto-filling is a feature that is available on the metadata definition level. When you open the Metadata Editor and select any field of the metadata there is an Autofilling property (under the Advance tab). You can select one of the following values:
| Name | Date type | Description |
| default_value | any type | When the null value is assign to the field and the field is marked as non-nullable, the null is replaced by the value of Default property of the field |
| global_row_count | any numeric | Sequence number of the record in a data source starting from 0. The number isn’t reset for each input file while the wildcards are used in File URL (${DATAIN_DIR}/input*.txt) |
| source_row_count | any numeric | Sequence number of the record in data source, starting from 0. The number is reset to 0 for each input file while the wildcards are used in File URL (${DATAIN_DIR}/input*.txt) |
| metadata_row_count | any numeric | Similar to global_row_count. But when the reader component supports more than one type of output metadata (XMLExtract, XMLXPathReader) each metadata has a separate counter. |
| metadata_source_row_count | any numeric | Similar to source_row_count. But when the reader component supports more than one type of output metadata (XMLExtract, XMLXPathReader) each metadata has a separate counter. |
| source_name | string | Name of data source. For file readers it’s fully qualified path (ex. /home/user/input.csv), for DataGenerator it’s ID of graph component, SQL query for DBInputTable, fully qualified class name for JMSReader |
| source_size | any numeric | Size of the file in bytes. 0 for non-file readers. |
| source_timestamp | date | Date and time of the creation of the file. Empty (null) in all non-file readers. |
| reader_timestamp | date | Date and time when reader starts read data |
| row_timestamp | date | Date and time when the reader starts read the record |
| sheet_name | string | Name of the sheet, only in XLSDataReader |
| ErrCode | any numeric | Error code returned by database engine, only in DBExecute and DBOutputTable |
| ErrText | string | Error message returned by database engine, only in DBExecute and DBOutputTable |
Remember that any of these functions can be applied to a field not contained in a file, database table, generated data, or JMS message.
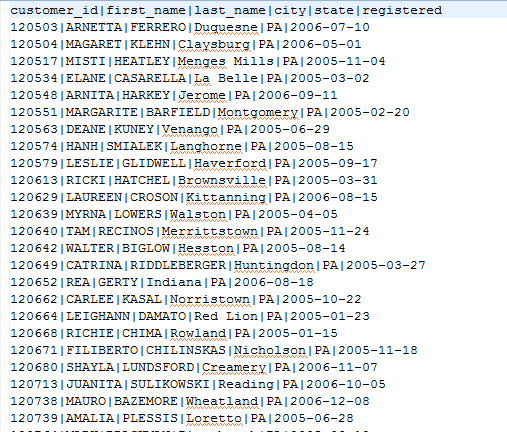
Imagine that you have an export of customers from a database in an Excel file. The Excel file is organized into many sheets; each sheet is named by a state abbreviation and contains only customers from one state. See figure below.
Now you want to merge all customers to one CSV file but for each customer you want to also store the state in separate column. It looks very easy :-). For CloverDX it is, not necessarily so for other ETL tools.
The final graph is very simple, there are only two components.
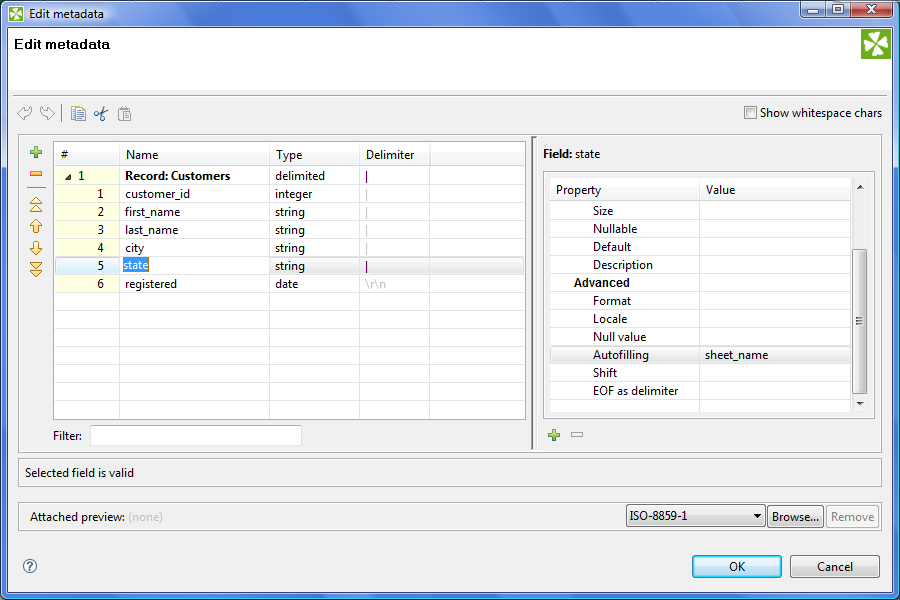
The most important part of this graph is hidden in the definition of the metadata on the edge. We have to enrich the metadata, which we created from the Excel file by using the proper wizard in CloverDX Designer, with a new field “state” by setting the Autofilling property to sheet_name as you can see below. And that’s all.
The Autofilling field can be placed on any position in a metadata definition. It’s conveniant that we place the autofilling fields at the end of the metadata definition, after the field with the record delimiter. But this conveniance does not apply when the same metadata are also used for writing to a flat file (in our case). Thus we moved the autofilling fields to the position before the field with a record delimiter.
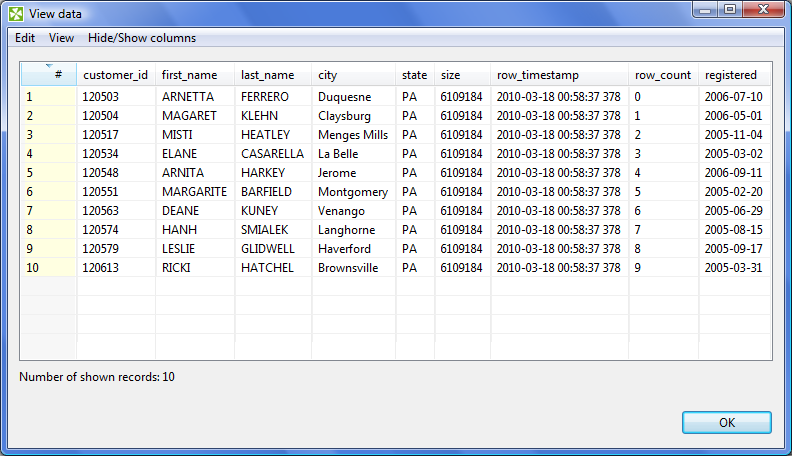
When you run the graph, you will get the following results:
You can use multiple autofilling fields with different functions at the same time to get better quality information from the file. For example, you can get the file name and the sheet names at the same time. Or you can get the number the records, etc. For example, when the following auto-filling functions are used (sheet_name, source_size, row_timestamp, global_row_count), the result will look like this:
Remember that only the edges connected to the output port(s) of the following reader components can use the auto-filling functionality:
DBOutputTable and DBExecute can use only two error auto-filling functions – ErrCode and ErrText.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}